


umsCodeGenerator
mappingSchema
Page for mappingSchema in general
mappingSchema とは?
mappingSchema は、データの構造とデコード・エンコードの処理の対応関係(マッピング) を規定する汎用的なスキーマ言語です。 このスキーマ言語とは、文書の集合を規定するための言語です。 たとえば、XML 文書のスキーマ言語のひとつとして RELAX NG が用いられています。
われわれは、RELAX NG を基に、テキスト形式やバイナリ形式の文書のためのスキーマ言語 UMS の規定を 進めています。 RELAX NG と UMS の仕様は、以下から入手することができます。
UMS とは?
UMS(Universal Mapping Schema)は、シーケンシャルデータの デコード・エンコードの処理を規定する文法です。
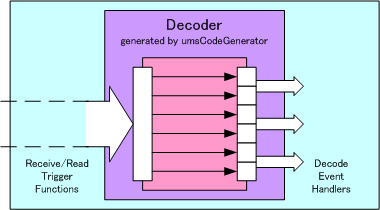
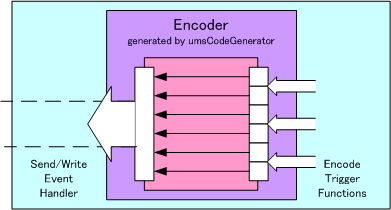
プログラムは一般にデータを入出力します。 多くの場合データはシーケンシャルです。 入力ではデータを書式に従いデコードする必要があります。 出力ではデータを書式に従いエンコードする必要があります。 例えば、以下の図では 外側の箱がプログラムを、 内側の箱がシーケンシャルデータを示しています。 内側と外側の箱に挟まれた部分が、 デコード・エンコードの処理です。
シーケンシャルデータのデコードの例
シーケンシャルデータのエンコードの例
mapping definition とは?
mappingSchema の文法に従った記述を mapping definitionと呼んでいます。 mapping definitionは、XML で記述できます。 今のところ XML でしか記述できません。 mappingSchema の文法の全体はまだ明文化されていません。 文法のサブセット (umsCodeGenerator の処理系が処理できる範囲) は XML のスキーマ (RELAX NG) で記述され、処理系とともに配布されています。
mapping definition は シーケンシャルデータのスキーマ(書式の定義)と アプリケーションプログラムインターフェース を組み合わせたものです。 mapping definitionを どのように作り上げるかは、事例毎に選ぶことができます。 シーケンシャルデータのスキーマ を規定し、これを処理する プログラム を作るか、あるいは、逆に アプリケーションプログラムインターフェース に沿う形で シーケンシャルデータの書式を決めても構いません。 例えば二つのシステム間でデータをやり取りする場合には、まず、受け渡される シーケンシャルデータのスキーマを双方の合意の 下に規定し、次に、 アプリケーションプログラムインターフェース の部分を、別々に付与することで、それぞれの mapping definitionを得ることができます。
mapping definitionに従った デコード・エンコードの処理 プログラムを手作業で作ることができきます。 しかし、この手作業の手間を省きたい場合、あるいは、定義どおり間違えず処理を 作りこみたいのならば、umsCodegenerator のような mappingSchema の処理系に処理を任せる と良いでしょう。 mappingSchema の処理系には、幾つかのタイプが考えられます。 mapping definitionから ソースコードを生成するタイプのもの、あるいは mapping definitionを 動的に読み込む汎用なライブラリなどです。 ある mapping definition (デコード・エンコード) を実現するには多数の処理アルゴリズムが存在します。 将来、事例の特性に応じ使い分けられるようになると良いですね。
Required knowledge
Knowledge of XML and its name space is required for usage of mappingSchema since mappingSchema is a schema language described in XML (sorry, no description is available at this moment). mappingSchema shares philosophy and some definition with an XML schema language RELAX NG. Knowledge of RELAX NG is helpful to understand mappingSchema. Altough XML version of mappingSchema is very similar with that of RELAX NG, there is some difference (see difference).
How To
In troduction of software development with mappingSchema is found here (sorry in Japanese).
develop program with mappingSchema (sorry, in Japanese). Note: Mapping definition and tools used in this document is somewhat older than the recent implementation of umsCodeGenerator.
Development
is now on-going by myself (KM) and few members. To accelerate our development, any contribution or collaboration is welcome.
Mailing Lists
Please send mail Mailing List itself if you want to join.
- Users ML: ums_users@plain.isas.jaxa.jp
- Developpers ML: ums_devel@plain.isas.jaxa.jp
文法の設計ポリシー
- ツールの実装を隠蔽せよ。実装が見えてしまう場合、 記述できていないパラメータが存在する。文法を再考せよ。 例えば、ツール固有な内部 API の存在を意識させてはいけない。
- 極力自分たち (ums group) で考案しないこと。 可能なら要素の定義そのもの。 無理なら考え方を取り入れよ。
- 可能な限り少ない要素で構成せよ。 利便性のための2次的なものは、 1次的な定義に帰着できるようにする。
- 汎用なものを目指せ。文法がその分煩雑になって構わない。
- Encode と decode の対称性に留意する。 XML - XML syntax はその実現を目指すが、 XML - language syntax はそもそも実現不能である。
(-KM-)
PDF版ドキュメントの制限事項
本ドキュメントは、Apache Forrestを利用して記述しています。 PDF版には以下の見苦しい点があります。ご了承下さい。
- 箇条書きの記号が「?」に文字化けして表示されてしまいます。
- 表中の文章の折り返しがずれることがあります。
- 図が挿入されません。
Specification of mapping definition
1. mapping definition の仕様
mapping definition は 大きく分けて3つの部分の定義から構成されます。
- データ構造
- プログラミング言語の処理
- データ構造とプログラミング言語の処理の対応(マッピング)
それぞれの部分を 空間 と呼びます。 mappingSchema の0.4版では、 以下のURIをそれぞれの 空間 に割り当て、 それぞれに対して接頭辞を対応させています。
| 定義 | 名前空間 URI | 名前空間接頭辞 | |
|---|---|---|---|
| データ構造 | http://ums.isas.jaxa.jp/0.4/dat | dat | |
| C言語 | http://ums.isas.jaxa.jp/0.4/clng | clng | |
| プログラミング言語の処理 | Java | http://ums.isas.jaxa.jp/0.4/java | java |
| Perl | http://ums.isas.jaxa.jp/0.4/perl | perl | |
| マッピング | http://ums.isas.jaxa.jp/0.4 | (接頭辞なし) |
1.1 データ構造の定義
データ構造を定義するためには、 byte 要素、 bit 要素、 list 要素の子に、 data 要素または value 要素を記述します。
以下の定義は、1バイトの符号あり整数からなるデータ構造を表します。 この定義に登場する いずれの XML 要素 も データ構造の空間に属しています。
<dat:byte enocde="signed" length="1">
<dat:data type="byte"/>
</dat:byte>
1.2 プログラミング言語の処理の定義
現在、プログラミング言語の処理の定義として二つの syntax が存在します。
- XML-XML syntax
- XML-language syntax
データ構造の記述に XML-XML syntax と XML-language syntax の区別はありません。
1.2.1 プログラミング言語の処理の定義(XML syntax)
XML syntax において、プログラミング言語の処理を定義するためには、 'lang:value-of'要素 の子に、 'lang:data'要素 または 'lang:value'要素 を記述します。
以下の定義は、1バイトのデータの値を持つ変数 var を表します。 この定義に登場する いずれの XML 要素 も 言語の空間に属しています。
<lang:value-of select="var">
<lang:data type="byte"/>
</lang:value-of>
1.2.2 プログラミング言語の処理の定義(Language syntax)
Language syntax において、言語での処理を定義するためには、 変数の代入式の形式で、 'lang:data'要素 または 'lang:value'要素 を記述します。
以下の定義は、1バイトのデータの値を持つ変数 var を表します。 この定義に登場する XML 要素 、XML 要素の外側に書かれた 部分のいずれも言語の空間に属しています。
var = <lang:data type="byte"/>;
<lang:data type="byte"/> = var;
1.3 データ構造とプログラミング言語の処理の対応の定義
データ構造の定義と、プログラミング言語の処理の定義を組み合わせ、両者の対応を定義します。
1.3.1 データ構造とプログラミング言語の処理の対応の定義(XML syntax)
XML syntax において、データ構造とプログラミング言語の処理の対応を定義するためには、 byte 要素、 bit 要素、 list 要素の子に lang:value-of 要素 を記述し、この要素の子に、 lang:data 要素 または lang:value 要素 を記述します。
以下の定義は、1バイトのデータの値を持つ変数 var に1バイトの符号あり整数からなる データ構造を対応させています。 この定義に登場する dat:byte 要素 は データ構造の空間、 lang:value-of 要素 は 言語の空間、 data 要素 は マッピングの空間に属しています。
<dat:byte enocde="signed" length="1">
<lang:value-of select="a">
<data type="byte"/>
</lang:value-of>
</dat:byte>
XML syntax の、デコード/エンコードについての mapping definition は以下のようになります。
| 定義 | data | value |
|---|---|---|
| データ構造 |
<dat:byte enocde="signed" length="1"> <dat:data type="byte"/> </dat:byte> |
<dat:byte enocde="signed" length="1"> <dat:value type="byte">1</dat:value> </dat:byte> |
| プログラミング言語の処理 |
<lang:value-of select="var"> <lang:data type="byte"/> </lang:value-of> |
<lang:value-of select="var"> <lang:value type="byte">1</lang:value> </lang:value-of> |
| マッピング |
<dat:byte enocde="signed" length="1">
<lang:value-of select="a">
<data type="byte"/>
</lang:value-of>
</dat:byte>
|
<dat:byte enocde="signed" length="1">
<lang:value-of select="a">
<value type="byte"></value>
</lang:value-of>
</dat:byte>
|
1.3.2 データ構造とプログラミング言語の処理の対応の定義(Language syntax)
Language syntax において、データ構造とプログラミング言語の処理の対応を定義するためには、 byte 要素、 bit 要素、 list 要素の子に 変数の代入式の形式で、 lang:data 要素 または lang:value 要素 を記述します。
以下の定義は、1バイトのデータの値を持つ変数 var に1バイトの符号あり整数からなるデータ構造を対応させています。 このパターンに登場する dat:byte 要素 は データ構造の空間、 data 要素 は マッピングの空間、その他の部分が言語の空間に属しています。
<dat:byte enocde="signed" length="1">
a = <data type="byte"/>;
</dat:byte>
<dat:byte enocde="signed" length="1">
<data type="byte"/> = a;
</dat:byte>
Language syntax の、デコードについての mapping definition は以下のようになります。
| 定義 | data | value |
|---|---|---|
| データ構造 |
<dat:byte enocde="signed" length="1"> <dat:data type="byte"/> </dat:byte> |
<dat:byte enocde="signed" length="1"> <dat:value type="byte">1</dat:value> </dat:byte> |
| プログラミング言語の処理 |
<lang:data type="byte"/> = a; |
<lang:value type="byte">1</lang:value> = a; |
| マッピング |
<dat:byte enocde="signed" length="1"> <data type="byte"/> = a; </dat:byte> |
<dat:byte enocde="signed" length="1"> <value type="byte">1</value> = a; </dat:byte> |
エンコードについての mapping definition は以下のようになります。
| 定義 | data | value |
|---|---|---|
| データ構造 |
<dat:byte enocde="signed" length="1"> <dat:data type="byte"/> </dat:byte> |
<dat:byte enocde="signed" length="1"> <dat:value type="byte">1</dat:value> </dat:byte> |
| プログラミング言語の処理 |
a = <lang:data type="byte"/>; |
<lang:value type="byte">1</lang:value> = a; |
| マッピング |
<dat:byte enocde="signed" length="1"> a = <data type="byte"/>; </dat:byte> |
<dat:byte enocde="signed" length="1"> a = <value type="byte">1</value>; </dat:byte> |
2. RELAX NG との違い? - 2005/06/28追記
RELAX NG は XML 文書に "限定" して使用するものです。 mappingSchema は、より広い文書で使用するためのものです。 第1に、このことにより差が生じます。
2つ目の違いは、"実装" をどう意識するかで生じます。 複数の実装が存在する場合、その相互運用のために、適用範囲を絞りこむ必要が出てきます。 - 今のところ - mappingSchema には、そういう制約は設けておらず、 適用範囲を明示するのはツールの義務であり、使用範囲を選択するのはユーザに任されています。
これらの違いの多くは "制約" の違いとなって現れます。 - 今のところ - mappingSchema の文法自身は"制約" を極力設けないないようにしています。 以下には、mappingSchema では許容されるが RELAX NG では 許容されないパターンの例を列挙します。
2.1 注釈 (外来の属性及び要素の取り扱い) - 2005/07/21追記
RELAX NG では外来の属性及び要素は取り除かれます (see RELAX NG 4.1)。 mappingSchema では外来の属性及び要素は「無視されます」。以下の例は
<element name="A">
<other:comment>
<element name="B">
<text/>
</element>
</other:comment>
</element>
RELAX NG では
<element name="A"/>
と、等価ですが mappingSchema では
<element name="A">
<element name="B">
<text/>
</element>
</element>
と、等価になります。
2.2 難解な書式 - 2005/08/01更新
mappingSchema では下記の記述が「可能」です。
<byte encode="txt">
<data type="int"/>
</byte>
<byte encode="txt">
<data type="int"/>
</byte>
たとえば、これは '123456' という文字列にマッチします。 2 つのデータ項目がそれぞれどの部分文字列にマッチするかは 一意に決まりません。以下の 5 通りの可能性があります。
- '12345' 及び '6'
- '1234' 及び '56'
- '123' 及び '456'
- '12' 及び '3456'
- '1' 及び '23456'
このようなデータのデコードには労力がかります。 そして、なにより、取り扱える処理系が限られてきてしまうため、 使うべきではありません。
なお、下記のパターンは RELAX NG (see 7.2) でも mappingSchema でも許容されません (list の子として現れる場合を除く)。
<data type="int"/>
<data type="int"/>
3. 制約事項
umsCodeGenerator で処理するにあたり、mapping definition では以下の制約があります。
- optional 要素、oneOrMore 要素、zeroOrMore 要素のネストの深さは、最大 32 です。
- list 要素のネストの深さは、最大 32 です。
- define/ref の再帰定義はできません。
- define 要素の子孫に、optional 、oneOrMore、zeroOrMore を記述することはできません。
- dat:*//ums:* という経路は許されません。
- XML syntax において、デコード/エンコード関数のインターフェースは固定です。
- Language syntax においてコード記述可能な部分は、XML syntax の <package>、<class>、<function>、<arg>、<return>、<var>、<array>、 <value-of>、<callFunction>の部分です。 $TABLETOOLS_HOME/sample/tutorial に含まれる Language syntax の例を参考にしてください。
userGuide
grammar 要素
スキーマのルート要素
- 通常、 スキーマを記述する際のルート要素として用いられます。 start要素, define要素, include要素, ref要素 を用いる際は、常に必須になります。
- 単純なスキーマを記述する際には、 コンテナ もしくは サブコンテナ をルート要素に使えます。ただし、ref要素 などでマクロを参照することが出来なくなるため、複雑なスキーマの記述には不向きです(ただし、externalRef要素 により、外部ファイルを参照することは可能です)。
- XML形式において最上位に配置できる コンテナ は element要素 のみです。 サブコンテナ は配置できません。
属性
xmlns 属性
スキーマ自体の名前空間を指定します。
RELAX NG の名前空間の URI は、http://relaxng.org/ns/structure/1.0 です。
ns 属性
スキーマで定義する要素/属性のデフォルトの名前空間を設定します。これにより、接頭辞無しで名前を使うことが出来ます。
xmlns:xxxx 属性
この形式でも、スキーマで定義する要素/属性の名前空間を設定出来ます( xxxx に、使用する接頭辞名を入れます)。定義する要素/属性に複数の名前空間が存在する際は、複数の xmlns:xxxx 属性 が必要になります。また、ns 属性 との併用も出来ます。
子ノード
- 一つ以上の start要素 を子に持ちます。
使用例
例 1:
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/" xmlns:h="http://batz.org/"> <start> <element name="document"> <ref name="para"/> </element> </start> <define name="para"> <element name="h:para"> <empty/> </element> </define> </grammar>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「grammar要素 @ ぽかぽか RELAX NG 工房」
start 要素
XML 文書のルート要素を定義
- 文書のルート要素を指定します(XML Schema や DTD では、「文書へのスキーマの埋め込み」を前提としているため、スキーマ内でルート要素を指定することは出来ません)。
属性
combine 属性
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。とりうる コンテナ の組み合わせは文書の形式によって制約を受けます。
-
ref要素 でマクロを指定しても構いません(通常はこちらを用いることが多いでしょう)。
ただし、XML の場合、参照先の define要素 の子要素が element要素 である必要があります。
- XML 文書では、最上位に要素を一つだけ持ちます(ルート要素)。最上位の grammar要素 では、直下の子要素の element要素 で指定された要素が、ルート要素となります。指定するルート要素は、複数あっても構いません。ただし、複数から択一になるので、choice要素 を「かます」必要があります。その場合、実際に検証される文書では、スキーマ内で指定されたルート要素のいずれか一つをルート要素にすることが出来ます。
使用例
例 1: ref要素 を用いる方法
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/"> <start> <ref name="document"/> </start> <define name="document"> <element name="document"> <empty/> </element> </define> </grammar>
例 2: choice要素 を用い、ルート要素を複数指定する方法
この例の場合、 doc1, doc2 いずれもルート要素とすることが出来る。ただし、内容の違いに注意。
<start> <choice> <element name="doc1"> <text/> </element> <element name="doc2"> <empty/> </element> </choice> </start>
例 3: start要素 を複数使用する方法
実質的には、上記と全く同一。
<start> <element name="doc1"> <text/> </element> </start> <start combine="choice"> <element name="doc2"> <empty/> </element> </start>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「start要素 @ ぽかぽか RELAX NG 工房」
file 要素
出力ファイルを指定する要素
- 出力するファイルの範囲と、ファイルの basename を指定します。
- ums ファイルの basename を basename とした出力ファイルも、生成されます。
- grammar 要素の直下には置いてはなりません。とりうる コンテナ の組み合わせは文書の形式によって制約を受けます。
属性
basename 属性
ファイル名を指定します。必須です。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
使用例
例 1: 1ファイルに出力
以下の FileSample.ums から生成されたソースコードは、FileSample.java 、File.java に出力されます。
-
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <start> <file basename="File"> <java:class scope="abstract" name="FileSample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> <java:class name="FileSampleRecord" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> </file> </start> </grammar>
例 2: 複数ファイルに出力
以下の FileSample.ums から生成されたソースコードは、FileSample.java 、File.java 、FileRecord.java に出力されます。
-
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <start> <file basename="File"> <java:class scope="abstract" name="FileSample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> </file> <file basename="FileRecord"> <java:class name="FileSampleRecord" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> </file> </start> </grammar>
例 3: ファイル要素の入れ子
以下の FileSample.ums から生成されたソースコードは、FileSample.java 、File.java 、FileRecord.java に出力されます。
-
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <start> <file basename="File"> <file basename="File"> <java:class scope="abstract" name="FileSample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> </file> <file basename="FileRecord"> <java:class name="FileSampleRecord" xmlns:java="http://ums.isas.jaxa.jp/0.4/java"> ... </java:class> </file> </file> </start> </grammar>
注意事項
ファイルを出力する際は、ums ファイルの basename を basename とした出力ファイルも、生成されます。
include 要素
外部モジュールを取り込む要素
- 外部スキーマの定義を取り込むための要素です。
- 当然、取り込まれるスキーマは文法に則ったものでなければなりません。また、 grammar要素 をルート要素としないスキーマは取り込めません。替わりに externalRef要素 を用いてください。
- 必ず、 grammar要素 の直下に記述しなければなりません。その条件さえ満たしていれば、どこに置いても構いません。
- ref要素 で、外部スキーマに記述されたマクロを参照出来ます。ただし、定義されていないマクロを参照してはなりません。
- 異なる名前空間を持つスキーマも取り込むことが出来ます。このことにより、既に提供されている異なる種類のモジュールを単に組み合わせるだけで、名前空間の違いを配慮せずとも独自のスキーマを簡単に作ることが出来ます(当然、文書インスタンスでは、名前空間を考慮しなければなりません)。
属性
href 属性
- 取り込む外部スキーマ名を指定します。 値は URI です。
子ノード
- 単に取り込みたい場合は、空要素とします。
- その他、start要素, div要素, define要素 を子要素とすることが出来ます。
- include要素 直下の define要素 は、 include要素 で示される参照先のスキーマの定義の上書きをする場合にのみ用いられます。新たな定義をしたり、combine 属性 を用いた定義の結合をしたりすることは出来ません。
使用例
例 1: 再定義を含める場合
以下の一聯のファイルを例に挙げます。
- ファイル1: schema1.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/"> <start> <element name="document"> <ref name="para"/> </element> </start> <include href="schema2.rng"> <define name="em-content"> <!-- "em-content" の再定義 --> <text/> </define> </include> </grammar>
- ファイル2: schema2.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/"> <define name="para"> <element name="em"> <ref name="em-content"/> </element> </define> <define name="em-content"> <empty/> </define> </grammar>
以上の場合、 schema1.rng の内容は、以下の内容と等価になります (マクロの展開はしておりません)。
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/"> <start> <element name="document"> <ref name="para"/> </element> </start> <define name="para"> <element name="em"> <ref name="em-content"/> </element> </define> <define name="em-content"> <text/> <!-- define 要素によって上書きされた --> </define> </grammar>
例 2: 異なる名前空間を有するスキーマの取り込み
以下の一聯のファイルを例に挙げます。
- ファイル1: schema1.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://lena.org/"> <start> <element name="document"> <ref name="para"/> </element> </start> <include href="schema2.rng"/> </grammar>
- ファイル2: schema2.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" ns="http://batz.org/"> <define name="para"> <element name="em"><empty/></element> </define> </grammar>
以上の場合、 schema1.rng の内容は、以下の内容と等価になります。
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0" xmlns:lena="http://lena.org/" xmlns:batz="http://batz.org/"> <start> <element name="lena:document"> <ref name="para"/> </element> </start> <define name="para"> <element name="batz:em"><empty/></element> </define> </grammar>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「include要素 @ ぽかぽか RELAX NG 工房」
define 要素
マクロを定義する要素
- 一聯のパターンをマクロ(外部から参照させるための「部品」)として利用したい場合、そのパターン群を define要素 の中身とします。いくつかのファイルに分けて「モジュール」を作りたい場合、必携の要素となります。
- define要素 の中身は、常に ref要素 から参照されます。 externalRef要素, include要素 などでは参照出来ません。
- 常に grammar要素 もしくは include要素 の子要素として記述しなければなりません。 define要素 を入れ子にしたり、各種パターン要素の子要素としたりしてはなりません。
- 通常は、同一ファイル内で define要素 と ref要素 が対応します。 ただし、include要素 を用いて外部ファイルの取り込みを行っている場合は、参照元(ref要素) と参照先(define要素) が異なるファイル内に存在しても構いません。ただし、 ref要素 の参照先が取り込みファイルの中に存在しない場合はエラーとなります。
同じ名前を持つ複数の define要素
- grammar要素 の子要素として記述する場合は、combine 属性 で結合法則を明示しなければなりません。combine 属性 には、 choice もしくは interleave どちらかの値を取ることが出来ます。
- include要素 の子要素として記述する場合は、「定義の上書き」のみが可能です。当然マクロの名前は、 参照先の外部ファイルの中に含まれていなければなりません。新たなマクロの定義や、combine 属性 を用いた「定義の結合」は出来ません。
属性
name 属性
マクロの名前を定義します。name 属性 の属性値は NCName となっているため、名前空間が異なる要素/属性宣言の中でも、同じ名前を使って参照することが出来ます。ただし、接頭辞と名前を区切るための : は使用出来ません。ピリオドやハイフン、アンダースコアは利用できます。尚、大文字小文字は区別されるので、注意してください。
combine 属性
結合法則を明示します(詳しくは後述)。
子ノード
- 空の define要素 はあまりよろしくないと思います。モジュールの組み込みにおいて「記述不可能」の旨の初期値を定義したい場合は、empty要素 を子要素に入れるのが最適でしょう。ただし、ここで notAllowed要素 を用いるとややこしいことになるので、注意が必要です (詳しくは「notAllowed要素 の解説」にて)。
- 全てのパターン関聯要素もしくは element要素, attribute要素 などを子要素にすることが可能ですが、してはいけないものもあります。例えば、要素/属性名の排他定義(◎◎と△△以外の全ての要素を中身にするような定義)の中では、 define, ref 各要素によるマクロの取り込みが出来ません。例えば、次のような記述は不可能です。
<element> <anyName> <except> <!-- except 要素による排他法則の定義 --> <ref name="exceptRule"/> <!-- 取り込み不可能!! --> </except> </anyName> .... </element> <define name="exceptRule"> <choice> <name>abc</name> <name>def</name> </choice> </define>
ただし、ref要素, define要素 を使わず、直截 define要素 の中身を except要素 の中に記述すれば、全く問題はありません。
使用例
例 1: define要素 と include要素 を用いた例
- ファイル1: schema1.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0"> <start> <element name="document"> <ref name="para"/> <!-- マクロの参照 --> </element> </start> <include href="schema2.rng"/> <!-- 外部ファイル取り込み --> <define name="para" combine="choice"> <element name="strong"><empty/></element> </define> </grammar>
- ファイル2: schema2.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0"> <define name="para"> <!-- 外部ファイル中の define 要素 --> <element name="em"><empty/></element> </define> </grammar>
例 2: 上記と等価なスキーマ
上記のスキーマをマクロを使用しないで記述した場合、以下のようになります。
<?xml version="1.0"?>
<grammar xmlns="http://relaxng.org/ns/structure/1.0">
<start>
<element name="document">
<choice> <!-- define 要素の combine 属性による効果 -->
<element name="strong"><empty/></element>
<element name="em"><empty/></element>
</choice>
</element>
</start>
</grammar>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「define要素 @ ぽかぽか RELAX NG 工房」
ref 要素
マクロを参照する要素
- define要素 で定義されたマクロを、他のパターンの中で参照し、埋め込むための要素です。
- include要素 や externalRef要素 を使って外部ファイルを取り込んでいる場合は、異なるファイル間で ref要素 と define要素 が対応していても構いません。
- コンテナ の属性 (XML 文書なら要素/属性名) の定義の中では使用できません。
つまり、XML の name要素, anyName要素, nsName要素 の「置き換え」としては使えない、ということです。当然、要素や属性名の定義に関係した記述は「モジュール化」は出来ません。
- 入れ子の参照
自分自身が含まれるパターンを取り込んだり、参照先の定義に自分自身への参照先を記述したりすることも可能です。例えば、以下の記述では、 nest 要素が無限に入れ子可能であることが定義されています。
<define name="NestPattern"> <element name="nest"> <ref name="NestPattern"/> </element> </define>
XML において、このような入れ子が可能であるのは、大抵は要素の中身の定義内のみに限られます。属性の定義を入れ子にすることなどはもともと不可能なので、上記のような記述は出来ません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
name 属性
マクロ名を指定します。 NCName なので、コロンは使えません。アンダースコア、ハイフン、ピリオドは使用できます。大文字小文字は区別されますので、注意してください。また、参照先が define要素 で定義されていない場合はエラーになります。
ns,xmlns:xxx,datatypeLibrary 属性
共通属性 ns 属性 ,xmlns:xxxx 属性 , datatypeLibrary 属性 が使用できます。例えば、外部ファイルへの参照を行う場合、名前空間やデータ型の再定義をしたい際に使用出来ます。
子ノード
- 常に空要素。子ノードを持ちません。
使用例
例 1:
define要素 の説明を参照してください。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「ref要素 @ ぽかぽか RELAX NG 工房」
externalRef 要素
外部スキーマをマクロとして参照する要素
- 外部スキーマを、まるごとマクロとして参照、埋め込みを行うための要素です。
- include要素 が grammar要素 を最上位要素としたスキーマを取り込むのに対し、externalRef要素 は、主にそれ以外の要素が最上位要素であるスキーマを参照するのに用いられます。
- コンテナ の属性 (XML 文書なら要素/属性名) の定義の中では使用できません。
つまり、XML の name要素, anyName要素, nsName要素 の「置き換え」としては使えない、ということです。当然、要素や属性名の定義に関係した記述は「モジュール化」は出来ません。
- 一応、最上位要素としても記述できます。意味があるのかどうかはともかく、取り敢えず可能です。
- ref要素 との違いは、define要素 の中身を指定するか外部スキーマの内容を指定するかの違いだけで、原則として機能は全く同一です。つまり、externalRef要素 で参照される外部スキーマの書式は、define要素 の中身と成り得る書式と同一である必要があります。具体例に関しては後述します。
- grammar 要素の直下には置いてはなりません。
属性
href 属性
- 取り込む外部スキーマ名を指定します。 値は URI です。
ns,xmlns:xxx,datatypeLibrary 属性
共通属性 ns 属性 ,xmlns:xxxx 属性 , datatypeLibrary 属性 が使用できます。例えば、外部ファイルへの参照を行う場合、名前空間やデータ型の再定義をしたい際に使用出来ます(ただし、参照先で既に定義されている場合は、そちらが優先されます)。
子ノード
- 常に空要素。子ノードを持ちません。
使用例
例 1: externalRef要素 を使用した例
- schema1.rng
-
<?xml version="1.0"?> <grammar xmlns="http://relaxng.org/ns/structure/1.0"> <start> <element name="drinkshop"> <externalRef href="schema2.rng"/> <!-- 外部スキーマの参照 --> </element> </start> </grammar>
- schema2.rng (最上位要素は大抵パターン関聯要素 ; ここでは choice 要素)
-
<?xml version="1.0"?> <choice xmlns="http://relaxng.org/ns/structure/1.0"> <element name="favoriteItem"> <text/> </element> <element name="regularItem"> <text/> </element> </choice>
例 2: externalRef 要素を使わない場合
schema1.rng は、以下の記述と同一になります (強調部分は、 externalRef 要素によって取り込まれた記述)。
<?xml version="1.0"?>
<grammar xmlns="http://relaxng.org/ns/structure/1.0">
<start>
<element name="drinkshop">
<choice>
<element name="favoriteItem">
<text/>
</element>
<element name="regularItem">
<text/>
</element>
</choice>
</element>
</start>
</grammar>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「externalRef要素 @ ぽかぽか RELAX NG 工房」
parentRef 要素
親階層のマクロを参照する要素
- 通常、マクロを参照するためには ref要素 を用います。しかし、grammar要素 が入れ子になっている場合には、参照元の属する grammar要素 から外れた場所に存在するマクロは参照することが出来ません。
- parentRef要素 を用いることで、親階層に存在するマクロを参照することが出来ます。
- grammar要素 の入れ子や階層構造は、異る言語のスキーマを取り込むことによる「マクロのかち合わせ」を避けるための一つの方法です。しかし、記述が繁雑になるため、通常はあまり用いられません。
属性
name 属性
参照するマクロ名を明示します。
子ノード
(ref要素 と同様)
- 常に空要素。子ノードを持ちません。
使用例
例 1: ref要素 の場合
以下のスキーマを考えてみます。
<grammar xmlns="http://relaxng.org/ns/structure/1.0">
<define name="想い出の品1">
<value>卒業アルバム</value>
</define>
<start>
<element name="僕">
<choice>
<ref name="想い出の品1"/>
<grammar>
<start>
<element name="私">
<ref name="想い出の品2"/>
</element>
</start>
<define name="想い出の品2">
<value>ビーズのネックレス</value>
</define>
</grammar>
</choice>
</element>
</start>
</grammar>
grammar要素 が入れ子になっているため、僕要素にある想い出の品1のマクロは、私要素のそれとは「違う階層に属するもの」として扱われます。
ref要素 は「同じ grammar要素 の階層に存在するマクロ」しか参照しません。従って上記の例では、マクロそのものを移動させない限り、いかなるマクロ名を用いたとしても、以下の二種類の文書しか妥当として扱われません。
- <僕>卒業アルバム</僕>
- <僕><私>ビーズのネックレス</私></僕>
また、ref要素 では、私要素内から 想い出の品1 を参照することも出来ませんし、僕要素内から想い出の品2 を参照することも出来ません。
例 2: parentRef要素 を用いた場合
私要素内から親階層に存在する想い出の品1のマクロを参照する場合は、以下のように書き直します。
<grammar xmlns="http://relaxng.org/ns/structure/1.0">
<define name="想い出の品1">
<value>卒業アルバム</value>
</define>
<start>
<element name="僕">
<choice>
<ref name="想い出の品1"/>
<grammar>
<start>
<element name="私">
<parentRef name="想い出の品1"/>
</element>
</start>
<define name="想い出の品2">
<value>ビーズのネックレス</value>
</define>
</grammar>
</choice>
</element>
</start>
</grammar>
このようにすることで、私要素が取り得る中身は、想い出の品1、つまり「卒業アルバム」に変わります。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「parentRef要素 @ ぽかぽか RELAX NG 工房」
defineFuncitons 要素
関数宣言を行う要素
- 関数定義を行う際に用います。
属性
- この要素に固有な属性はありません。
制約
- start 要素、class 要素(java 名前空間の場合のみ)の子としてのみ現れることができます。
子ノード
- function 要素を子に持ちます。
使用例
例 1:
<defineFunctions>
<lang:function name="setValue">
<lang:arg type="int" name="iValue" direction="in"/>
<lang:return type="void"/>
</lang:function>
<lang:function name="getValue">
<lang:return type="int"/>
</lang:function>
</defineFunctions>
defineMapping 要素
マッピングを定義する要素
- データのマッピングを記述する際に用います。
- デコード・エンコード処理を行う関数が、マッピングにしたがって処理を行います。
属性
direction 属性
マッピングの方向を指定します。
- decode : デコードを行います。
- encode : エンコードを行います。
制約
- function 要素の子としてのみ現れることができます。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
使用例
例 1: decode
<defineMapping direction="decode" xmlns:txt="http://ums.isas.jaxa.jp/0.4/dat">
<txt:list encode="txt">
<txt:data type="token"/>
<lang:value-of select="strData">
<data type="token"/>
</lang:value-of>
<lang:callFunction expr="setStringValue( strData );"/>
<lang:value-of select="iData">
<data type="int"/>
</lang:value-of>
<lang:callFunction expr="setIntValue( iData );"/>
</txt:list>
</defineMapping>
例 2: encode
<defineMapping direction="encode" xmlns:txt="http://ums.isas.jaxa.jp/0.4/dat">
<txt:list encode="txt" delimiter=" ">
<lang:callFunction expr="strData = getStringValue();"/>
<lang:value-of select="strData">
<data type="token"/>
</lang:value-of>
<lang:callFunction expr="iData = getIntValue();"/>
<lang:value-of select="iData">
<lang:data type="int"/>
</lang:value-of>
</txt:list>
</defineMapping>
defineVariables 要素
変数宣言を行う要素
- 変数の定義を行う際に用います。
- start 要素の子として定義した場合は、グローバル変数、 fucntion 要素の子として定義して場合は、ローカル変数として扱われます。
属性
- この要素に固有な属性はありません。
制約
- start 要素、class 要素(java 名前空間の場合のみ)、function 要素の子としてのみ現れることができます。
子ノード
- 複数の array 要素、var 要素を持つことができます。
使用例
例 1:
<defineVariables>
<lang:array size="4096">
<lang:var type="char" name="strData"/>
</lang:array>
<lang:var type="int" name="iData"/>
</defineVariables>
group 要素
一聯のパターンを明示する要素
- 一聯の複数のパターンが切り離すことが出来ないものである場合、それらを group要素 を用いて明示します。
- コンテナ や サブコンテナ (XMLなら要素属性値、要素の中身) など様々な定義の中で使うことが出来ます。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
- この要素に固有な属性はありません。
子ノード
- 子ノードに様々なパターンを取り込み、choice要素 などと組み合わせることで、複雑な選択肢を作成することが可能になります。
- 子ノードには、 コンテナ (XMLなら要素や属性) や サブコンテナ の宣言が混在していても構いません。
- optional要素, choice要素, zeroOrMore要素 など、様々なパターンを子孫要素に入れることが出来ます。
- group要素 が出現しても、パターン出現順序は保持されます。
- ref 要素を中身にし、マクロを参照することが出来ます。
使用例
例 1: 親要素の属性値によって子要素の中身を変化させるスキーマ
<?xml version="1.0"?>
<element name="start" xmlns="http://relaxng.org/ns/structure/1.0">
<choice>
<group>
<attribute name="myway">
<value>1</value>
</attribute>
<element name="Japan-way"><empty/></element>
</group>
<group>
<attribute name="myway">
<value>2</value>
</attribute>
<element name="China-way><empty/></element>
</group>
</choice>
</element>
この場合、以下の文書は妥当な文書となります。
-
<?xml version="1.0"?> <start myway="1"> <Japan-way/> </start>
-
<?xml version="1.0"?> <start myway="2"> <China-way/> </start>
ただし、以下の文書は妥当ではありません。
-
<?xml version="1.0"?> <start myway="lena"> <!-- myway 属性の属性値は1か2のみ --> <Japan-way/> </start>
-
<?xml version="1.0"?> <start myway="1"> <China-way/> <!-- myway="1" のとき、許されるのは Japan-way 要素のみ --> </start>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「group要素 @ ぽかぽか RELAX NG 工房」
interleave 要素
順位不同の必須パターンを定義する要素
- 子要素に記述される一聯のパターンに関し、順位不同で必須の記述であることを示す要素です。group要素 が「順位を保持したグループ化」であるのに対し、interleave要素 は「順不同のグループ化」を明示する要素であると言えます。
- XML文書の属性の出現順位はもともと順位不同なので、attribute要素 の親要素として使用しても意味がありません。ただし、モジュールを用いて属性を増やしたい場合には、この要素の利用価値があるかと思われます。
- コンテナ や サブコンテナ (XMLなら要素属性値、要素の中身) など様々な定義の中で使うことが出来ます。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
- この要素に固有な属性はありません。
制約
interleave の直下に指定できる子要素の数は、最大「32」です。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
- choice要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
- interleave要素 でグループ化すべきパターンが同一である (要素なら要素、属性なら属性など) 方が理解しやすいですが、必ずしもそのようにしなければならない決まりはありません。
- ref 要素を中身にし、マクロを参照することが出来ます。
使用例
例 1:
例えば、以下のようなスキーマの記述があったとします。
<element name="doc"> <interleave> <element name="a"><empty/></element> <element name="b"><empty/></element> <element name="c"><empty/></element> </interleave> </element>
上記のスキーマに照らし合わせれば、以下の記述はいずれも妥当なものとなります。
- <doc><a/><b/><c/></doc>
- <doc><a/><c/><b/></doc>
- <doc><b/><a/><c/></doc>
- <doc><b/><c/><a/></doc>
- <doc><c/><a/><b/></doc>
- <doc><c/><b/><a/></doc>
例 2: group の interleave
以下のパターン
<interleave>
<group>
<element name="a"><text/></element>
<element name="b"><text/></element>
</group>
<element name="c"><text/></element>
</interleave>
は、以下にマッチします。
- <a/><b/><c/>
- <a/><c/><b/>
- <c/><a/><b/>
考えてみよう!
その 1: 入れ子の interleave 要素
interleave要素 直下に interleave要素 を置いても効果はありません。つまり、以下の記述例は、全く同一の機能を有します。
- 記述例1
-
<interleave> <ref name="a"/> <interleave> <ref name="b"/> <ref name="c"/> </interleave> </interleave>
- 記述例2
-
<interleave> <ref name="a"/> <ref name="b"/> <ref name="c"/> </interleave>
その 2: empty要素 を含んだ interleave要素
interleave要素 の子要素に1個以上の empty要素 が存在した場合、それらの empty要素 は、単に無視されます。
その 3: notAllowed要素 を含んだ interleave要素
interleave要素 の子要素に1個以上の notAllowed要素 が存在した場合、interleave要素 の内容そのものが無視され、1つの notAllowed要素 として認識されます。
上記の現象は、
- 他の記述に混じって、「不許可」というパターンも適用させなければならない。
- 元のパターン (ここでは interleave要素) そのものが「不許可」扱いされる。
- 元のパターン自体が「不許可というパターンを適用させるもの」と認識される。
と説明附けられます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「interleave要素 @ ぽかぽか RELAX NG 工房」
choice 要素
選択肢を定義する要素
- 子要素に記述される一聯のパターンに関し、それらのうちの一つを選ばせるために用いる要素です。
- コンテナ や サブコンテナ (XMLなら要素属性値、要素の中身) など様々な定義の中で使うことが出来ます。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
- この要素に固有な属性はありません。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
- 同一選択肢の中に入れるパターンは、出来るだけ同じ性質のもの(要素なら要素、属性なら属性など)を入れるのが望ましいと思われます。しかし文法がおかしくならない限りは、異種のパターンを同じ選択肢に入れることは可能です。例えば、附加情報を属性でも子要素でも現せるようにしたい場合には、要素の宣言パターンと属性の宣言パターンを同列の選択肢の中に記述する必要があります。
- ref 要素を中身にし、マクロを参照することが出来ます。
使用例
例 1: mapping の例 (XML-XML syntax)
以下のパターンは、'A' もしくは '2' にマッチします。 プログラミング言語では、これらをそれぞれ 変数 id の値 '1'、'2'に、対応させています。
-
<choice> <group> <dat:byte><dat:value>A</dat:value></dat:byte> <lang:value-of select="id"><lang:value>1</lang:value></lang:value-of> </group> <group> <dat:byte> <lang:value-of select="id"><value>2</value></lang:value-of> </dat:byte> </group> </choice>
例 2: mapping の例 (XML-language syntax)
例 1 は、以下のように書き直すことができます。 しかし、記述方法については、まだ決定していません。
- encode の例
-
<choice> <group> <lang:value>1</lang:value> = id; <dat:byte><dat:value>A</dat:value></dat:byte> </group> <group> <dat:byte> <value>2</value> = id; </dat:byte> </group> </choice> - decode の例
-
<choice> <group> <dat:byte><dat:value>A</dat:value></dat:byte> id = <lang:value>1</lang:value>; </group> <group> <dat:byte> id = <value>2</value>; </dat:byte> </group> </choice>
choice 直下の group の中に、 通常はその他のデータ定義が含まれます。 処理系に実装されたアルゴリズムは 全ての文法を取り扱えるとは限りません。 固定のための識別パターンは、 先頭で定義することが好まれます。
考えてみよう!
その 1: 入れ子の choice要素
choice要素 直下に choice要素 を置いても効果はありません。つまり、以下の記述例は、全く同一の機能を有します。
- 記述例1
-
<choice> <ref name="a"/> <choice> <ref name="b"/> <ref name="c"/> </choice> </choice>
- 記述例2
-
<choice> <ref name="a"/> <ref name="b"/> <ref name="c"/> </choice>
その 2: empty要素 を含んだ choice要素
要素の中身の定義に関し、empty要素 と、それ以外のパターンを示す要素が同時に子要素である場合、 2個目以降の empty要素 は効果がありません。notAllowed要素 の場合と違い、「空の記述 = 何も書かない状態」も許されることに注意してください(つまり、選択肢がオプション扱いされる)。
その 3: notAllowed要素 を含んだ choice要素
notAllowed要素 と、それ以外のパターンを示す要素が同時に子要素である場合、notAllowed要素 が書かれていないことと変わりません。
このことは、モジュールを設計する際に役に立ちます。例えば、デフォルトでは「記述不可能」としておき、モジュールを結合させることで選択肢を設置もしくは増やす、といったことが出来ます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「choice要素 @ ぽかぽか RELAX NG 工房」
optional 要素
出現の有無を任意にする要素
- 子要素に記述される一聯のパターンに関し、それらのパターンの出現を任意にする要素です。具体的に言えば、0回もしくは1回の出現を指示する働きを持ちます。
- とりわけ attribute要素 の親要素として用いることで、属性をオプション扱いとして定義出来ます(DTD では #IMPLIED の宣言に相当)。
- attribute要素 の子孫要素としては用いることが出来ません。
- コンテナ や サブコンテナ (XMLなら要素属性値、要素の中身) など様々な定義の中で使うことが出来ます。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
lang:occurs 属性
名前空間 lang に属する属性です。optional 内の処理を実行するかどうかを、事前に設定してください。
- decode : 「1」であれば、optional 内の処理を実行します。
- encode : 「1」であれば、optional 内の処理を実行します(encode 時は必須です)。
lang:occured 属性
名前空間 lang に属する属性です。optional の処理の後に設定されます。
- decode : optional 内の処理を実行できた場合は「1」、 実行できなかった場合は「0」が、指定された変数に代入されます。
- encode : 指定できません。
制約
- optional、oneOrMore、zeroOrMore を入れ子にできる最大数は、「32」です。
- ref 要素を中身にし、マクロを参照することが出来ます。 ただし、ソースコードの生成前に、define/ref が展開されている必要があります。
- lang:occurs 属性と、lang:occured 属性を同時に指定することはできません。 どちらか一方を必ず指定してください。
- occurs 属性に 0 または 1 以外の値を指定することはできません。エラーとなります。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
考えてみよう!
その 1: 連続する optional要素
連続する optional要素 の中身を、一つの optional要素 の中身としてまとめることは出来ません。以下に、その例を示します。
- 例1
-
<optional> <ref name="a"/> </optional> <optional> <ref name="b"/> </optional>
- 例2
-
<optional> <ref name="a"/> <ref name="b"/> </optional>
例1では、「aとbそれぞれが任意出現パターン」であるのに対し、例2では、「aとbとの並びが任意出現」となります。それぞれのパターンを任意出現パターンとして定義したい場合は、面倒でも独立した optional要素 の子要素として記述しなければなりません。
その 2: 出現順番に関して
choice要素, interleave要素 の子要素でない場合、定義の出現順番は保持されます。例えば、以下のスキーマを考えます。
<element name="p">
<optional>
<element name="a"><empty/></element>
</optional>
<optional>
<element name="b"><empty/></element>
</optional>
</element>
上記のスキーマに則った場合、以下の文書は妥当とはなりません。
<p><b/><a/></p>
つまり「オプション扱い」になると言っても、順序まで任意になるわけではないので、注意してください(順序を任意にしたい場合は、choice要素, interleave要素 の子要素とする必要があります)。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「optional要素 @ ぽかぽか RELAX NG 工房」
oneOrMore 要素
1回以上の繰り返しを定義する要素
- 子要素に記述される一聯のパターンに関し、それらのパターンが1回以上繰り返して出現することを指示する要素です。
- XML では、主に要素の中身の定義に対して用います。
- attribute要素 の直截の親要素として用た場合、その属性は必須属性と見倣されます(attribute要素 を element要素 直下に記述した場合と同様)。ただし、複数の同名の属性を記述出来るわけではないので、注意してください。
- attribute要素 の子孫要素としては用いることが出来ません。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
- 要素名に大文字が混じっていますので、記述には注意してください。
属性
lang:occurs 属性
名前空間 lang に属する属性です。繰り返し処理の回数を、事前に設定してください。
- decode : 指定された回数だけ、繰り返し処理を実行します。
- encode : 指定された回数だけ、繰り返し処理を実行します(encode 時は必須です)。
lang:occured 属性
名前空間 lang に属する属性です。oneOrMore の処理の後に設定されます。
- decode : 繰り返し数の解析結果が、指定された変数に代入されます。
- encode : 指定できません。
制約
- optional、oneOrMore、zeroOrMore を入れ子にできる最大数は、「32」です。
- ref 要素を中身にし、マクロを参照することが出来ます。 ただし、ソースコードの生成前に、define/ref が展開されている必要があります。
- lang:occurs 属性と、lang:occured 属性を同時に指定することはできません。 どちらか一方を必ず指定してください。
- lang:occurs 属性に 1 未満の値を指定することはできません。エラーとなります。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
使用例
例 1: mapping の例 (XML-XML syntax)
以下のパターンは、1 バイト以上のバイナリデータにマッチします。 変数 n に、バイト長を対応させています。
- decode の例
-
<oneOrMore lang:occured="n"> <dat:byte length="1"> <lang:value-of select="i"> <data type="int"/> </lang:value-of> </dat:byte> <callFunction expr="pushValue( i );"/> </oneOrMore> - encode の例
-
<oneOrMore lang:occurs="n"> <callFunction expr="i = popValue();"/> <dat:byte length="1"> <lang:value-of select="i"> <data type="int"/> </lang:value-of> </dat:byte> </oneOrMore>
decode では、繰り返し数の解析結果が変数 n に代入されます。また、 encode では、変数 n で指定された回数分繰り返しが行われます。
例 2: mapping の例 (XML-language syntax)
例 1 は、以下のように書き直すことができます。 しかし、記述方法については、まだ決定していません。
- decode の例
-
<oneOrMore> <dat:byte length="1"> <callFunction expr="pushValue( <data type="int"/> );"> </dat:byte> n = </oneOrMore>; - encode の例
-
<oneOrMore> = n; <dat:byte length="1"> <data type="int"/> = <callFunction expr="popValue();"/> </dat:byte> </oneOrMore>
例 3: JAVA での mapping の例 (XML-language syntax)
JAVA には Interator や Collection など集合を取り扱うのに 便利なクラスがそろっています。これらを使用することもできます。
- Iterator を用いた encode
-
<oneOrMore> <lang:var class="Byte" name="b" interator="iterator"> <dat:byte length="1"> <data type="byte"/> = b.byteValue(); </dat:byte> </lang:var> </oneOrMore> - List を用いた encode
-
<oneOrMore> <lang:var class="Byte" name="b" collection="list"> <dat:byte length="1"> <data type="byte"/> = b.byteValue(); </dat:byte> </lang:var> </oneOrMore> - List を用いた decode
-
<oneOrMore> <dat:byte length="1"> list.add( new Byte(<data type="byte"/>) ); </dat:byte> </oneOrMore>
が、美しい記法ではないですね。
考えてみよう!
その 1: 連続する oneOrMore要素
連続する oneOrMore要素 の中身を、一つの oneOrMore要素 の中身としてまとめることは出来ません。以下に、その例を示します。
- 例1
-
<oneOrMore> <ref name="a"/> </oneOrMore> <oneOrMore> <ref name="b"/> </oneOrMore>
- 例2
-
<oneOrMore> <ref name="a"/> <ref name="b"/> </oneOrMore>
例1では、「aが1回以上出現した後、bが1回以上出現するパターン (aa…bb…)」であるのに対し、例2では、「aとbが、この順番を保持したまま1回以上出現 (abab…)」となります。
その 2: 出現順番に関して
- choice要素, interleave要素 の子要素でない場合、定義の出現順位は保持されます。
- oneOrMore要素 の子要素の中で、choice要素, interleave要素 が存在しない部分は、定義の出現順位は保持されます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「oneOrMore要素 @ ぽかぽか RELAX NG 工房」
zeroOrMore 要素
0回以上の繰り返しを定義する要素
- 子要素に記述される一聯のパターンに関し、それらのパターンが任意の回数(0回含む)繰り返して出現することを指示する要素です。
- XML では、主に要素の中身の定義に対して用います。
- attribute要素 の直截の親要素として用いた場合、その属性はオプション属性と見倣されます (optional要素 の子要素として記述した場合と同じ)。同名の属性を複数記述出来るようになるわけではありませんので、注意してください。
- attribute要素 の子孫要素としては用いることが出来ません。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
- 要素名に大文字が混じっていますので、記述には注意してください。
属性
lang:occurs 属性
名前空間 lang に属する属性です。繰り返し処理の回数を、事前に設定してください。
- decode : 指定された回数だけ、繰り返し処理を実行します。
- encode : 指定された回数だけ、繰り返し処理を実行します(encode 時は必須です)。
lang:occured 属性
名前空間 lang に属する属性です。zeroOrMore の処理の後に設定されます。
- decode : 繰り返し数の解析結果が、指定された変数に代入されます。
- encode : 指定できません。
制約
- optional、oneOrMore、zeroOrMore を入れ子にできる最大数は、「32」です。
- ref 要素を中身にし、マクロを参照することが出来ます。 ただし、ソースコードの生成前に、define/ref が展開されている必要があります。
- lang:occurs 属性と、lang:occured 属性を同時に指定することはできません。 どちらか一方を必ず指定してください。
- lang:occurs 属性に 0 未満の値を指定することはできません。エラーとなります。
子ノード
- 複数の コンテナ もしくは サブコンテナ を子要素に持つことが出来ます。 interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
考えてみよう!
その 1: 連続する zeroOrMore要素
連続する zeroOrMore要素 の中身を、一つの zeroOrMore要素 の中身としてまとめることは出来ません。以下に、その例を示します。
- 例1
-
<zeroOrMore> <ref name="a"/> </zeroOrMore> <zeroOrMore> <ref name="b"/> </zeroOrMore>
- 例2
-
<zeroOrMore> <ref name="a"/> <ref name="b"/> </zeroOrMore>
例1では、「aが1回以上出現した後、bが0回以上出現するパターン (aa…bb…)」であるのに対し、例2では、「aとbが、この順番を保持したまま0回以上出現 (abab…)」となります。
その 2: 出現順番に関して
- choice要素, interleave要素 の子要素でない場合、定義の出現順位は保持されます。
- zeroOrMore要素 の子要素の中で、choice要素, interleave要素 が存在しない部分は、定義の出現順位は保持されます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「zeroOrMore要素 @ ぽかぽか RELAX NG 工房」
text 要素
一般テキストの包含を指示する要素
- 要素の中身が子要素を含まない普通のテキスト(DTD の #PCDATA に相当)、もしくは属性値が普通のテキスト(DTD の CDATA に相当)であることを指示したい場合、それを (原稿が間違っています。用語が定義されていません!!) として明示します。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
- この要素に固有な属性はありません。
子ノード
- 常に空要素。子ノードを持ちません。
考えてみよう!
その 1: パターン
- 連続する text要素 は、一つの text要素 と見倣されます(ただし、同じツリー内にあっても、何らかの要素を挟んで存在する場合は、また別の話になります)。
- choice要素 内に複数の text要素があった場合、それらは一つの text要素 と見倣されます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「text要素 @ ぽかぽか RELAX NG 工房」
value 要素
特定値のテキストを要求する要素
- ある要素の中身もしくは属性値において、ある特定の値を持つテキストのみを許すようにしたい場合、その値を value要素 として明示します。
- element要素 もしくは attribute要素 の子孫要素として主に用いられます。
- grammar 要素の直下には置いてはなりません。
属性
type 属性
データ型を指定します。
- type 属性 が存在する場合、先祖(もしくは自分自身の)要素の datatypeLibrary 属性 によるデータ型ライブラリに応じたデータ型が適用されます。当然ですが、value要素 の中身は、そのデータ型に準じたものでなければなりません。
- type 属性 が存在しない場合は、 type="token" が(暗示的に)指定されたものと見倣され、先祖要素の datatypeLibrary 属性 による指定は無視されます(RELAX NG 由来のデフォルトのデータ型になる)。
制約
value 要素は、 Mapping definition の以下の位置のみに現れることができます。
- - lang:value-of - lang:value -
- - dat:container - dat:value -
- - dat:container - lang:value-of - ums:value -
ただし、ここで dat:container は dat:byte, dat:bit, rng:element, rng:attribute などを示しています。以下は obsolete です。
- - lang:value-of - dat:container - ums:value -
子ノード
テキストノードを子に一つ持ち特定の値を定義します。
使用例
例 1: 要素の中身
例えば、 好物 要素の中身を ステーキ、ショートケーキ、クリームシチューの三つからの択一にしたい場合は、以下のような記述が考えられます。
- スキーマ(の一部)
-
<element name="好物"> <choice> <value>ステーキ</value> <value>ショートケーキ</value> <value>クリームシチュー</value> </choice> </element>
- 実際の XML 文書(の断片)の一例
-
- <好物>ショートケーキ</好物> <!-- 正しい -->
- <好物>ハンバーグ</好物> <!-- エラー -->
例 2: 属性値
例えば、 画像 要素において ファイル 属性と 配置 属性を定義し、ファイル属性は任意のテキスト、配置属性には 右、左 のどれかの値を入れられるようにしたい場合、以下のような記述が出来ます(要素は空要素とします)。
- スキーマ(の一部)
-
<element name="画像"> <empty/> <attribute name="ファイル"> <text/> </attribute> <attribute name="配置"> <choice> <value>右</value> <value>左</value> </choice> </attribute> </element>
- 実際の XML 文書(の断片)の一例
-
- <画像 ファイル="RheineRiver.jpg" 配置="左"/> <!-- 正しい -->
- <画像 ファイル="ObiRiver.gif" 配置="中央"/> <!-- エラー -->
以上の例のように、value要素 は、choice要素 と用いることが多いかと思われます。また、値を一つしか持ち得ないような場合は、choice要素 を介さず、value要素 を直截子要素として記述することが可能です。
DTD の如く「何も入れなかった場合の初期値」を決定することは出来ません。RELAX-NGはあくまで「XML文書の検証」をするための機構であり、何かしらの前提をスキーマ自身に盛りこむべきではない、との理念に基づいているからです。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「value要素 @ ぽかぽか RELAX NG 工房」
data 要素
特定のデータ型を明示的に指定する要素
- 普通のテキストではなく、数値(整数や実数)や URI, Base64 などといった、特殊な形のテキストのみを許容したい場合、それを data要素 として明示します。
- 要素の中身としても、属性値としても使えます。それぞれ、element要素, attribute要素 の中身として data要素 を記述します。
- 先祖要素において、 datatypeLibrary 属性 によって、取り込むデータ型ライブラリを明示する必要があります。
属性
type 属性
データ型を指定します(これは必須です)。取り得る値は、ライブラリに完全に依存します。
制約
data 要素は、 Mapping definition の以下の位置のみに現れることができます。
- - lang:value-of - lang:data -
- - dat:container - dat:data -
- - dat:container - lang:value-of - ums:data -
ただし、ここで dat:container は dat:byte, dat:bit, rng:element, rng:attribute などを示しています。以下は obsolete です。
- - lang:value-of - dat:container - ums:data -
以下の場合は、データが「不定」になります。
- decode 時の lang:data
- encode 時の dat:data
子ノード
- 空要素にした場合、データの制限は type 属性 の内容のみに依存します。
- param要素 を中身に入れることで、データ型にさらなる制限を附加させることが出来ます。param要素 を複数入れても構いません。
使用例
例 1: プロフィールの作成
W3C XML Schema Part 2 のライブラリを用いた例を紹介致します。尚、param要素 を併用した例に関しては、「param要素」の項を御覧ください。
プロフィール に、氏名, 年齢, 誕生日, サイトURI を入れたい場合は、以下のようなスキーマが作られるでしょう(簡単のため、要素の出現順序は固定とします)。
- スキーマ例
-
<?xml version="1.0"?> <element name="プロフィール" xmlns="http://relaxng.org/ns/structure/1.0" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <element name="氏名"> <data type="string"/> <!-- 通常の文字列 --> </element> <element name="年齢"> <data type="integer"/> <!-- データは整数 --> </element> <element name="誕生日"> <data type="date"/> <!-- データは日附(ISO 8601形式) --> </element> <element name="サイト"> <data type="anyURI"/> <!-- データは URI --> </element> </element>
- 妥当な XML 文書の一例
-
<?xml version="1.0"?> <プロフィール> <氏名>真田ゆり子</氏名> <年齢>18</年齢> <誕生日>1985-05-11</誕生日> <サイト>http://www.sanada.org/</サイト> </プロフィール>
- 妥当でない XML 文書の一例
-
<?xml version="1.0"?> <プロフィール> <氏名>金子時男</氏名> <年齢>さんじゅうに</年齢> <!-- 整数でない --> <誕生日>昭和40年5月1日</誕生日> <!-- ISO 8601 形式でない --> <サイト>金子プロ</サイト> <!-- URI でない --> </プロフィール>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「data要素 @ ぽかぽか RELAX NG 工房」
param 要素
データ型に附加情報を与える要素
- 特定のデータ型に関し、何らかの制限や情報を附加させるための要素です。
- name 属性 が制限を課す条件名、中身がその条件の値を、それぞれ示します。name 属性 の属性値と param要素 の中身は、データ型ライブラリの定義に依存します(RELAX-NG 内部では、特に定義されていません)。
- 常に data要素 の直下に置かなければなりません。
属性
name 属性
制限を課す条件名を示します。とりうる条件名は、データ型ライブラリの定義に依存します(RELAX-NG 内部では、特に定義されていません)。
子ノード
- 子にテキストノードを一つ持ち条件のパラメタを示します。とりうる値は、データ型ライブラリの定義に依存します(RELAX-NG 内部では、特に定義されていません)。
- 中身は常にテキストです。空の param要素 は望ましくないと思われます。
使用例
例 1: 「プロフィール」の例
data要素と同じ例。 プロフィールには氏名, 年齢のみが入れられるとします。
制限すべき事項と具体的制限
- 氏名は通常の文字列で、文字数は1 〜 10 文字とします。
- 年齢は整数値で、範囲は0-150とします。
実際の記述例
- スキーマ例
-
<?xml version="1.0"?> <element name="プロフィール" xmlns="http://relaxng.org/ns/structure/1.0" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes"> <element name="氏名"> <data type="string"> <param name="minLength">1</param> <param name="maxLength">10</param> </data> </element> <element name="年齢"> <data type="integer"> <param name="minInclusive">0</param> <param name="maxExclusive">150</param> </data> </element> </element>
- 妥当な XML 文書の一例
-
<?xml version="1.0"?> <プロフィール> <氏名>真田ゆり子</氏名> <!-- 中身は5文字 --> <年齢>18</年齢> <!-- 数値は1-150の範囲内 --> </プロフィール>
- 妥当でない XML 文書の一例
-
<?xml version="1.0"?> <プロフィール> <氏名>寿限無寿限無海砂利水魚</氏名> <!-- 11文字! --> <年齢>250</年齢> <!-- 150より上! --> </プロフィール>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「param要素 @ ぽかぽか RELAX NG 工房」
except 要素
排他法則を記述するための要素
- 特定の要素/属性名を対象から外したい場合や、特定のデータを排除したい場合は、 except要素 を用いて排他法則を明記します。
- 要素/属性名の排他処理のための anyName要素, nsName要素 各要素の子要素として記述します。
- data要素 の子要素にすることも出来ます。この場合、except要素 の中身として、各種のパターンを記述することが可能です。ただし、テキストにそぐわない要素を記述することは出来ません。例えば、element要素, attribute要素 は記述出来ません。
属性
- この要素に固有な属性はありません。
子ノード
except要素 の中身は、nsName要素, name要素, choice要素 のみです。
使用例
例 1: 特定の名前を排除する
例えば、公開情報 要素の中にはいかなる要素も複数個入れられる一方、 極秘 要素と 機密 要素のみを排除させるようにするには、以下のようにします。
<element name="公開情報">
<zeroOrMore>
<element>
<anyName>
<except>
<name>極秘</name>
<name>機密</name>
</except>
</anyName>
<text/> <!-- いかなる要素においても、中身はテキストとする -->
</element>
</zeroOrMore>
</element>
属性名においても、同様に制馭が出来ます。
例 2: 要素の振り分け
記入欄 要素にはいかなる要素も複数個入れられ、中身にはテキストが記入できるとします。また、 記入が無い場合は、 記入無し 要素(空要素)を一つだけ含むようにしたいとします。この場合、choice要素 を用いて、以下のようにスキーマを記述出来ます。
- スキーマ(の断片)の例
-
<element name="記入欄"> <choice> <zeroOrMore> <element> <anyName> <except> <name>記入無し</name> <!-- 記入無し 要素は特別扱い --> </except> </anyName> <text/> </element> </zeroOrMore> <element name="記入無し"> <!-- 記入無し 要素はこちらで定義 --> <empty/> </element> </choice> </element> - 妥当な XML 文書(の断片)1
-
<記入欄> <名前>ラーナ=シャルロット</名前> <年齢>16</年齢> <好きな食べ物>ショートケーキ、パイナップル</好きな食べ物> </記入欄>
- 妥当な XML 文書(の断片)2
-
<記入欄> <記入無し/> </記入欄>
- 妥当でない XML 文書
-
<記入欄> <name>Y. Imada</name> <記入無し/> <!-- 記入無し 要素以外には、何も入れられない !! --> </記入欄>
例 3: 特定の名前空間に属する名前を排除する
例えば、名前空間URI http://www.evil.com/ に属する要素だけを排除し、あとはいかなる要素も入れられるようにするためには、例えば以下のように記述します。
<element name="記入欄">
<zeroOrMore>
<element>
<anyName>
<except>
<nsName ns="http://www.evil.com/"/>
</except>
</anyName>
<text/> <!-- いかなる要素においても、中身はテキストとする -->
</element>
</zeroOrMore>
</element>
例 4: データの排他処理
例えば、何らかのデータを扱っている中で、未定義のデータ(例えば undefined や 未定義, none)を弾きたい場合には、以下のような記述が考えられます。
<element name="情報">
<data type="string">
<except>
<choice>
<value>undefined</value>
<value>未定義</value>
<value>none</value>
</choice>
</except>
</data>
</element>
あるいは、怪しい記述が含まれているデータ(例えば 押売, 強盗, 死 を含むもの)を弾くのにも用いることが可能です。ここでは、データ型ライブラリとして W3C XML Schema のデータ型を使います。
<element name="活動内容">
<data type="string"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<except>
<data type="string">
<param name="pattern">[.\s]*(押売|強盗|死)[.\s]*</param>
</data>
</except>
</data>
</element>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「except要素 @ ぽかぽか RELAX NG 工房」
empty 要素
空の記述を定義する要素
- XML文書の要素の中身など、ある箇所において「空の記述」を定義する要素です。
- しかし大抵は、XML文書の空要素の定義もしくは属性セットの初期値の定義内で使われることが多いかと思われます。
- ルート要素とすることが出来ます。利用価値の是非はともかく、一応可能です。
- コンテナ や サブコンテナ (XMLなら要素属性値、要素の中身) など様々な定義の中で使うことが出来ます。
- grammar 要素の直下には置いてはなりません。
属性
- この要素に固有な属性はありません。
子ノード
- 常に空要素。子ノードを持ちません。
考えてみよう!
その 1: パターン内での empty要素 の振舞い
- 複数の連続する empty要素 は、一つの empty要素 と見倣されます。
- interleave要素, group要素, oneOrMore要素, zeroOrMore要素, optional要素 内の子要素に empty要素 が含まれていた場合、その empty要素 は単に無視されます。ただし、empty要素 しか存在しない場合は、そのパターンは、一つの empty要素 と見倣されます。
- choice要素 内の empty要素 に関しては、後述します。
その 2: choice要素 内
- choice要素 の子要素が全て empty要素 (あるいはそれと見倣されるもの)であった場合、choice要素 自体が一つの一つの empty要素 と見倣されます。
-
choice要素 の子要素に、他のパターンに混じって empty要素 が存在した場合、「記述無し」という定義が選択肢の中に入ります。例えば、次のような記述を考えてみます。
<choice> <value>うどん</value> <value>そば</value> <value>ラーメン</value> <empty/> </choice>
この場合、empty要素 は無視されず、「うどん」「そば」「ラーメン」という値が記述出来るのに加え、「何も記述しない」パターンをも許してしまいます。とりわけ、必須記法を choice要素 で選択させる場合には、気を附けなければなりません。
その 3: element要素 内
element要素 の子要素が empty要素 (と属性宣言のパターン)のみである場合、その element要素 で定義される要素は空要素と定義されます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「empty要素 @ ぽかぽか RELAX NG 工房」
notAllowed 要素
記述を不許可に設定する要素
- 記述を不許可にするための要素です。既にあるパターンの効果を打ち消すのにも使えます。
- choice要素 を用いた選択肢の「初期値」として使えなくもありませんが、取り扱いには注意が必要です。親要素への効果の波及が著しいため、非常に使いづらい要素の一つとなっております。
- notAllowed要素 を含んだ構造要素(choice要素 など)の振舞いには、注意が必要です。詳しくは後述します。
- 一応、ルート要素としても記述可能です。そのようにして意味があるかどうかは知りませんが、取り敢えずは出来ます。
- パターン中に記述された(もしくは参照先のマクロに含まれた) notAllowed要素 は、親要素に対して著しい影響を及ぼします。
- grammar 要素の直下には置いてはなりません。
属性
- この要素に固有な属性はありません。
子ノード
- 常に空要素。子ノードを持ちません。
考えてみよう!
その 1: choice要素 の中の notAllowed要素
- choice要素 の子要素の中に一つ以上の notAllowed要素 が含まれた場合、notAllowed要素 は無視され、その他のパターンのみが適用されます。
- ただし、choice要素 の中に notAllowed要素 もしくは notAllowed要素 と見倣される記述 (notAllowed要素 を子要素に持つ interleave要素 など)のみが存在する場合、その choice要素 自体が、一つの notAllowed要素 と見倣されます。
その 2:
- 原則として、連続する notAllowed要素 は、一つの notAllowed要素 と見倣されます。
- notAllowed要素 が必然的に適用されるパターンでは、もとのパターンの効果は無視され、全て一つの notAllowed要素 に置き換わります。例えば、notAllowed要素 を一つ以上子要素に有する attribute要素, group要素, interleave要素, oneOrMore要素 がこれに相当します。
- zeroOrMore要素, optional要素 の子要素に notAllowed要素 が存在していた場合、これらのパターン自体が単に無視されます (notAllowed要素 には置き換わりません)。
- except要素 の子要素の中に一つ以上の notAllowed要素 が含まれた場合、 except要素 そのものの効果が消えます。
- notAllowed要素 を一つ以上子要素に持つ element要素 では、要素宣言そのものが破毀されます (の筈ですが、うまく検証プログラムで処理出来ないこともあります)。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「notAllowed要素 @ ぽかぽか RELAX NG 工房」
DATA
Text Binary
bit 要素
ビットストリームを表すコンテナ
- スキーマのルート要素にすることが出来ます。このスキーマを単独で用いる場合、文書インスタンス全体に対応します。
属性
length 属性
長さをビット数で指定できます。省略した場合任意の長さが許されます。
encode 属性
データのエンコードを指定します。
- テキストエンコード txt, バイナリエンコード signed, unsigned, ieee754single,ieee754double などを指定できます。
- 省略された場合は、直近の祖先の enocde 属性が用いられます。それで決まらない場合は txt が指定されたものとして扱われます。
子ノード
- 子として、複数のコンテナ (byte要素, bit要素) もしくは一つのサブコンテナを持つことができます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
- マッピング定義を行う場合は、value-of 要素を子孫に持ちます。
使用例
例 1: length 属性が指定された場合。
この例では、10 bit 分だけ処理が行われます。
<txt:bit length="10" encode="signed">
<data type="int"/>
</txt:bit>
例 2: length 属性が指定され ていない場合。
この例では、type が int であるため、32 bit 分、処理が行われます。
<txt:bit encode="signed">
<data type="int"/>
</txt:bit>
例 3: bit 要素の入れ子。
bit 要素が入れ子になっている場合、length 属性が指定されていなければ、 直近の祖先で指定された length 属性を元に、 処理を行う bit 数が決められます。 この例では、singned type のデータを 10 bit、unsigneInt type のデータを 6 bit 処理します。
<txt:bit length="16>
<txt:bit length="10" encode="signed">
<data type="int"/>
</txt:bit>
<txt:bit encode="unsigned">
<data type="unsignedInt"/>
</txt:bit>
</txt:byte>
byte 要素
バイトストリームを表すコンテナ
- スキーマのルート要素にすることが出来ます。このスキーマを単独で用いる場合、文書インスタンス全体に対応します。
属性
length 属性
長さをバイト数で指定できます。省略した場合任意の長さが許されます。
encode 属性
データのエンコードを指定します。
- テキストエンコード txt, バイナリエンコード signed, unsigned, ieee754single,ieee754double などを指定できます。
- 省略された場合は、直近の祖先の enocde 属性が用いられます。それで決まらない場合は txt が指定されたものとして扱われます。
子ノード
- 子として、複数のコンテナ (byte要素, bit要素) もしくは一つのサブコンテナを持つことができます。
- interleave要素, optional要素, zeroOrMore要素 などを子に持つことも可能です。
- マッピング定義を行う場合は、value-of 要素を子孫に持ちます。
line 要素
1行データを定義する要素
- データの最後に改行を付加する際に用います。
属性
encode 属性
データのエンコードを指定します。
- テキストエンコード txt, バイナリエンコード signed, unsigned, ieee754single,ieee754double などを指定できます。
- 省略された場合は、直近の祖先の enocde 属性が用いられます。それで決まらない場合は txt が指定されたものとして扱われます。
制約
- defineMapping 要素の子孫としてのみ現れることができます。
子ノード
- 子として、複数のコンテナ (byte要素, bit要素) を持つことができます。
使用例
例 1: line 要素の用いた記述
以下のパターンは、整数値のみが1行に書かれたデータにマッチします。
-
<txt:line> <txt:byte encode="txt"> <lang:value-of select="iData"> <data type="int"/> </lang:value-of> </txt:byte> </txt:line>
例 2: line 要素を用いない記述
例 1 と同等のパターンを、line 要素を用いずに記述した場合、以下のようになります。 改行文字を、直接 value 要素で指定します。
-
<txt:byte encode="txt"> <lang:value-of select="iData"> <data type="int"/> </lang:value-of> </txt:byte> <txt:byte encode="txt"> <txt:value type="string"> </txt:value> </txt:byte>
list 要素
空白区切りのデータ列挙を明示する
- 空白文字で区切られた一聯の列挙型データは、list要素 で明示出来ます。
- 要素の中身としても、属性の値としても使用出来ます。区切りは通常のスペース, タブ文字, 改行文字などが使えます。当然ですが、全角空白は空白とは見倣されません。
- XML では、通常、常に element要素, attribute要素, define要素 の子孫でなければなりません。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
separator 属性
区切り文字を表します。
- decode : 区切り文字が連続した場合、それらを1つの区切り文字として扱います。
- encode : 終端の token の後に、指定した区切り文字を出力しません。
delimiter 属性
区切り文字を表します。
- decode : 区切り文字が連続した場合、空データとして扱います。
- encode : 終端の token の後に、指定した区切り文字を出力します。
属性の省略
separator 属性が指定された場合と同等の動きをします。 その際、区切り文字は、" "、"\t"、"\n"、"\r"となります。
制約
区切り文字に、文字列を指定することはできません。
「A,,B」というように空文字がある際、数値の場合はエラーとして扱います。 文字データの場合は、長さ 0 の文字として扱います。
子ノード
- value要素, data要素 を中身に置くことが出来ます。ただし、text要素 など、それ自体に空白を含み得るデータを置くことは出来ません。区切りの関係が不明確になるためです。
- XML では element要素, attribute要素 を子孫に入れてはいけません。
- 子要素パターンの出現順位の関係は保たれます(要素の中身, 属性値いずれにも当て嵌まります)。順位不同にしたい場合は、interleave要素, choice要素 どを適宜使う必要があります。
使用例
例 1: 地図中での進行順路
ゲームマップなどで宝の在処を指し示したい場合に、入口からどのように進めば何が得られるかをデータ化したい場合があるかも知れません。その場合、空白区切りで一画面毎の順路を記述しておくと便利な場合があるでしょう。以下にスキーマと XML 文書(の断片)の一例を示します。
- スキーマ断片の一例
-
<element name="宝"> <attribute name="名前"><text/></attribute> <list> <oneOrMore> <choice> <value>上</value> <value>下</value> <value>左</value> <value>右</value> </choice> </oneOrMore> </list> </element> - 妥当な XML 文書の断片の一例
-
<宝 名前="エメラルドロッド"> 上 上 左 下 左 上 上 右 下 </宝>
- 妥当でない XML 文書の一例
-
<宝 名前="黄金の兜"> 上 上 左 下 左 中 上 右 下 <!-- "中" が含まれている --> </宝>
例 2: 色の列挙
Cascading Style Sheets では、 枠線の色指定は空白区切りで列挙します(上, 右, 下, 左の順)。この表記を XML の属性(ここでは色属性とします)で実現させるための一つの方法として、list要素 を使うことを考えます。以下の例では、 RGB.datatype は既に定義済 (#RRGGBB のみの形を許す) とします。ついでに、基本的な色 (赤, 青, 黄色)に関しては、名前を使えるとします。
- スキーマ断片の一例
-
<element name="枠線"> <empty/> <attribute name="色"> <list> <oneOrMore> <choice> <ref name="RGB.datatype"/> <value>赤</value> <value>青</value> <value>黄色</value> </choice> </oneOrMore> </list> </attribute> </element> - 妥当な XML 文書断片の例
-
- <枠線 色=" #222255 #ab7766 #00a3b1 #ff0022 "/>
- <枠線 色=" 黄色 #ab7766 赤 "/>
以上の例では、色指定の個数制限は設けられておりません。もう少し複雑な記述をすれば、ある程度の制限を設けることは可能です。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「list要素 @ ぽかぽか RELAX NG 工房」
XML
element 要素
要素を宣言するための要素
- 文書インスタンスの要素を定義する要素です。
- XMLでは文書インスタンス内のルート要素が文書全体に一致します。
- スキーマのルート要素にすることが出来ます。このスキーマを単独で用いる場合、文書インスタンス全体に対応します。
属性
name 属性
- 要素名を指定します。要素名は Qualified name なので、名前空間を考慮する必要があります。
- name 属性 を記述しない場合は、name要素 で指定します。
- もしくは、anyName要素 を子要素にすることで、すべての要素を許容することが出来ます。その際、except要素 を使うことで、適用すべきでない要素名を除去することも可能です。
ns 属性
指定する要素及びその子孫要素のデフォルトの名前空間 URI を指定できます。
xmlns:xxxx 属性
grammar要素 と同様、xmlns:xxxx 属性 を使用することもできます。
xmlns 属性
element要素 をルート要素とする場合は、スキーマ自体の名前空間 (http://relaxng.org/ns/structure/1.0) を宣言しなければなりません。
子ノード
- element要素 (及び element要素 を子孫に持つ choice要素 など) を入れ子にすることで、要素の包含関係を明示することが出来ます。
- その他、element要素 には、様々な要素を入れることが出来ます。通常は、choice要素, zeroOrMore要素 などのパターン制馭要素と共に用いることが多いでしょう。
- element要素 (あるいは、element要素を子孫要素に持つ choice要素 など) を並べた場合、文書インスタンス中では、element要素 の出現順序通りに要素が出現していなければなりません。
- (同じ名前空間に属する)同じ要素名の element要素 を複数異なる場所に設置することが可能です。これにより、同じ要素の入れ子を定義したり、要素の出現する場所によって異なる中身や属性を定義したりすることが出来ます。
- ref 要素を中身にし、マクロを参照することが出来ます。
使用例
例 1:
名前空間 URI http://lena.com に属する p 要素をルート要素として宣言。中身は通常のテキストデータとする。
<?xml version="1.0"?> <element name="p" ns="http:lena.com" xmlns="http://relaxng.org/ns/structure/1.0"> <text/> </element>
例 2:
p 要素 を宣言。 p 要素の中身は、 a1, a2 要素が a1, a2 の順で各一つづつ出現しなければならない。
<element name="p"> <element name="a1"><text/></element> <element name="a2"><text/></element> </element>
例 3:
book 要素を除く任意の要素において、 book 要素が一つだけ出現する。 book 要素の中身はテキスト。
<element> <anyName> <except><name>book</name></except> </anyName> <element name="book"><text/></element> </element>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「element要素 @ ぽかぽか RELAX NG 工房」
attribute 要素
要素の属性を定義する要素
- lang や space の属性を定義する場合、名前空間を考慮する必要はありません。
- 複数の attribute要素 を用いることで、一つの要素に複数の属性を定義出来ます。その際、element要素 要素と異なり、 実際の属性の出現順位は、attribute要素 の出現順位に依存しません。つまり、定義さえされていれば、実際には任意の順番で属性を記述出来る、ということです。
- element要素 直下に記述された場合、その属性は必須属性となります(DTD では、 #REQUIRED の宣言に相当)。任意属性 (DTD で言う #IMPLIED) としたい場合は、optional要素 の中に attribute要素 を入れる必要があります。
- oneOrMore要素, zeroOrMore要素 を親要素とすることは可能ですが、同じ属性名を持つ属性を複数書けるようにはなりません。optional要素 は普通に使用出来ます。
属性
name 属性
- 属性名を定義します。element要素 と同様、このほかに name要素 で定義、もしくは anyName要素 を子要素とすることで、任意の名前の属性を入れられるように定義することも可能です。ここで定義される名前は「有修飾名(qualified name)」なので、名前空間を考慮する必要があります。
ns,xmlns:xxxx 属性
- grammar要素, element要素 と同様、ns 属性 や xmlns:xxxx 属性 を用いて、局所的に名前空間を変更することが出来ます。
- 要素に名前空間を指定したとしても、通例属性はローカルなままで用います。この場合 xmlns:xxxx 属性 を、attribute要素 で定義する必要はありません。
子ノード
- 子ノードにより、その属性の属性値が定義されます。
- text要素 を用いるのが一般的ですが、value要素, data要素 や choice要素 を子孫に持つことが出来ます。
- element要素, attribute要素 を子孫要素としてはなりません。
- 当然ですが、ref要素 を子孫要素とする場合、その参照先に、上記の禁じられた要素が存在してはなりません。
- ref 要素を中身にし、マクロを参照することが出来ます。
使用例
例 1:
item 要素において、 lang 属性と、xlink:href 属性を定義。 lang 属性は任意、 xlink:href 属性は必須とする。いずれも属性値は任意テキストとする。
<element name="p">
<optional>
<attribute name="lang">
<text/>
</attribute>
</optional>
<attribute name="xlink:href" xmlns:xlink="http://www.w3.org/1999/xlink">
<text/>
</attribute>
<text/> <!-- p要素の中身はテキストとする -->
</element>
例 2:
color 属性を定義。属性値は、 red, blue, yellow いずれかの値を取り得る。
<attribute name="color"> <choice> <value>red</value> <value>blue</value> <value>yellow</value> </choice> </attribute>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「attribute要素 @ ぽかぽか RELAX NG 工房」
mixed 要素
テキスト(ノード)の混在を許す要素
- 要素と共に任意の位置にテキストの混在を許したい場合、そのパターンを mixed要素 として明示します。いわゆる「インライン要素」を作るのに便利です。
- grammar 要素の直下には置いてはなりません。
- スキーマのルート要素に用いることが出来ます。ただし、そのスキーマは単独では用いることは出来ず、 externalRef 要素の参照先としてのみ利用できます。
属性
- この要素に固有な属性はありません。
子ノード
- 子ノードを持つことが必須です。
- 指定が無い場合、子ノードの出現順位や出現回数そのものは保持されます。
- 子ノードに value要素, data要素 を持つことが出来ます。ただし、text要素 など、それ自体に空白を含み得るデータを持つことは出来ません。区切りの関係が不明確になるためです。
- element要素, attribute要素 を子孫に入れてはいけません。
- 子要素パターンの出現順位の関係は保たれます(要素の中身, 属性値いずれにも当て嵌まります)。順位不同にしたい場合は、interleave要素, choice要素 などを適宜使う必要があります。
使用例
例 1:
説明要素の中に、インライン要素として 名前, 所属, 場所各要素がこの順番で出現するようにさせるためには、以下のようなスキーマ(の断片)を作成します。実際の文書の例も示します。
- スキーマ
-
<element name="説明"> <mixed> <element name="所属"><text/></element> <element name="名前"><text/></element> <element name="場所"><text/></element> </mixed> </element>
- 妥当な文書(の断片)例
-
<説明> 今日、<所属>テニス部</所属>の<名前>バッツ</名前>は、 <場所>202号教室</場所>にて会合に参加している。 </説明>
例 2:
interleave要素, zeroOrMore要素 などと組み合わせることにより、より高度な表現が可能になります。例えば、a要素と b 要素が任意のテキストを折り混ぜて任意の位置に任意の個数だけ並べられるようにするには、以下のように記述します。参考までに、mixed要素 を使わない例も併せて示します。
- mixed 要素を使った例
-
<element name="element"> <mixed> <interleave> <zeroOrMore> <element name="a"><text/></element> </zeroOrMore> <zeroOrMore> <element name="b"><text/></element> </zeroOrMore> </interleave> </mixed> </element> - choice 要素を使った例
-
<element name="element"> <zeroOrMore> <choice> <element name="a"><text/></element> <element name="b"><text/></element> <text/> </choice> </zeroOrMore> </element>
上記の例では、choice要素 を用いた方がすっきりしたものが出来ます。ただし、「どれかを必須要素としたい」場合などは、choice要素 を使うことは出来ません。
例えば、「インライン要素a, b要素があり、a 要素は0個以上、 b 要素は一つだけ必ず出現しなければならない」というパターンを作りたい場合は、 mixed要素 と interleave要素 を使う必要があるでしょう。以下にスキーマの例を示します。
<element name="element">
<mixed>
<interleave>
<zeroOrMore>
<element name="a"><text/></element>
</zeroOrMore>
<element name="b"><text/></element>
</interleave>
</mixed>
</element>
考えてみよう!
その 1:
empty要素, text要素 もしくは attribute要素 だけを含む mixed要素 は、単一の text要素 と見倣されます。
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「mixed要素 @ ぽかぽか RELAX NG 工房」
name 要素
要素, 属性の名前を宣言する要素
- 通常、要素や属性の名前を明示するためには、element要素, attribute要素 の name 属性 を用います。しかし、name要素 を用いても等価な結果が得られます。
- name要素 を使うと、要素, 属性の名前の決め方を柔軟にすることが出来ます。
注意すべき点
- name要素 の中身は有修飾名(qname)です。デフォルトの名前空間を持たない要素には、常に接頭辞が必要です。
- 属性に使う場合は、常に「グローバルな属性」を想定しているため、常に接頭辞が必要になりますし、ローカルな属性の定義にも使えません。ただし、名前空間の宣言を全く行わない場合に限り、接頭辞が不要になります(と言うより、そもそも使えない)。
- 二つ以上並べて書いてはなりません。ただし、choice要素 の子要素に複数記述し、名前の選択をさせることは可能です。
- name要素 を使った場合、element要素, attribute要素 で name 属性 を使ってはなりません。
属性
- この要素に固有な属性はありません。
使用例
例 1: name要素 と name 属性
以下の二つのスキーマ(の断片)は、等価なものと見倣されます。接頭辞の有無には関係ありません。
- 例1
-
<element name="庭:植物"> <text/> </element>
- 例2
-
<element> <name>庭:植物</name> <text/> </element>
例 2: 名前に選択肢を設ける
例えば、ルート要素が 家屋 要素でも 田畑 要素でも良く、かつこれらの要素の取り得る中身が同一(名前, 場所が書ける)である場合は、以下のようなスキーマが書けるでしょう。
- スキーマ例
-
<?xml version="1.0"?> <element xmlns="http://relaxng.org/ns/structure/1.0"> <choice> <name>家屋</name> <name>田畑</name> </choice> <element name="名前"><text/></element> <element name="場所"><text/></element> </element>
- 妥当な XML 文書の例1
-
<?xml version="1.0"?> <家屋> <名前>牧野啓文宅</名前> <場所>山里市五丁目三番地</場所> </家屋>
- 妥当な XML 文書の例2
-
<?xml version="1.0"?> <田畑> <名前>ラベンダー牧場</名前> <場所>柏原郡海里町3-2-1</場所> </田畑>
属性に関して
ns 属性 でデフォルトの名前空間が明示されている場合、以下の二つは等価ではありません。名前空間の仕様により、「デフォルトの名前空間に属した属性」を表すことが出来ないためです。
- 例1
-
<element name="ゲーム" ns="http://www.sanada.org/"> <attribute name="対象年齢"> <text/> </attribute> <empty/> </element>
- 例2
-
<element name="ゲーム" ns="http://www.sanada.org/"> <attribute> <name>対象年齢</name> <text/> </attribute> <empty/> </element>
ただし、xmlns:xxxx 属性 による宣言がなされている場合、以下の二つは等価です。当然ですが、娯楽:対象年齢 属性はグローバル属性になります。
- 例1
-
<element name="娯楽:ゲーム" xmlns:娯楽="http://www.sanada.org/"> <attribute name="娯楽:対象年齢"> <text/> </attribute> <empty/> </element>
- 例2
-
<element name="娯楽:ゲーム" xmlns:娯楽="http://www.sanada.org/"> <attribute> <name>娯楽:対象年齢</name> <text/> </attribute> <empty/> </element>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「name要素 @ ぽかぽか RELAX NG 工房」
anyName 要素
任意の要素/属性の存在を許すための要素
- ある特定の要素において、任意の名前を有する要素や属性の存在を許したい場面が存在するかも知れません(例えば、部分的な検証を行いたい場合などがそれに当たります)。そのような場合、その要素/属性の名前を anyName要素 として明示します。
- name 属性 を持たない element要素, attribute要素 の子要素として用いられます。逆に言えば、anyName要素 を子要素に持つ element要素, attribute要素 には、 name 属性 を附属させてはいけません。
属性
- この要素に固有な属性はありません。
子ノード
- anyName要素 を空要素にした場合、任意の要素もしくは属性の存在を許すことになります。
- except要素 を子要素に持つことが出来ます。その場合、except要素 内に記述された名前を持つ要素や属性は対象外となります。
使用例
例 1:
自己紹介 要素において、いかなる要素を複数個勝手に加えて良い(中身はテキスト)一方で、氏名 要素を常に必須要素として記述させたい場合は、以下のようにスキーマを作れるでしょう。
- スキーマ
-
<element name="自己紹介"> <interleave> <!-- 氏名要素を含め、要素の並び方は順位不同とする。 --> <zeroOrMore> <element> <!-- 氏名要素以外の任意の要素 --> <anyName> <except> <name>氏名</name> </except> </anyName> <text/> </element> </zeroOrMore> <element name="氏名"><text/></element> </interleave> </element> - 正しい XML 文書(の断片)
-
<自己紹介> <氏名>鈴木栄作</氏名> <!-- 氏名は必須要素 --> <職業>総理大臣</職業> <趣味>スキー、テニス</趣味> </自己紹介>
- 間違った XML 文書(の断片)
-
<自己紹介> <!-- 氏名要素が欠落 --> <好物>鰯の丸干し</好物> <特技>踊り</特技> </自己紹介>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「anyName要素 @ ぽかぽか RELAX NG 工房」
nsName 要素
特定の名前空間に属する名前全てを指定する要素
- ある特定の名前空間に属するあらゆる種類の要素, 属性名の存在を許可したい場合、その名前指定を nsName要素 で明示します。
- 「あらゆる種類の名前」という意味で、anyName要素 と類似の働きをします。しかし anyName要素 が名前空間の内容に関わらず全ての名前を許可するのに対し、nsName要素 では名前空間が特定されるという違いがあります。
- (当然と言えば当然ですが) nsName要素 を子要素に持つ element要素, attribute要素 では、 name 属性 は使えません。
属性
ns 属性
- 名前空間の明示は ns 属性 で行います。スキーマ自体を接頭辞無しで用いている場合は、xmlns 属性 は使えません(ただし、スキーマ自体の要素や属性に接頭辞が附属されている場合を除く)。
- ns 属性 が省略された場合は、先祖要素に記述された ns 属性 の値が適用されます。
子ノード
anyName要素 と同様、except要素 を用いた排他パターンのみが許されます。except要素 と name要素 を使うことにより、特定の要素, 属性名を対象から除くことが出来ます。
使用例
例 1: 特定の名前空間に属する任意の属性を記述する
名前空間 http://www.garden.co.jp/ に属する任意の属性を埋め込みたい場合、以下のような記述が考えられます。
<element name="喫茶店"> <zeroOrMore> <attribute> <nsName ns="http://www.garden.co.jp/"/> <text/> </attribute> </zeroOrMore> … </element>
以上のスキーマで、以下の XML 文書(の断片)は妥当なものとなります。
<喫茶店 庭:種類="ローズガーデン" 庭:広さ="10m^2"
xmlns:庭="http://www.garden.co.jp/">
…
</喫茶店>
尚、複数の種類の名前空間を許したい場合は、異る ns 属性 値を有する nsName要素 を複数並べて書きます。以下に例を示します。
<element name="喫茶店"> <zeroOrMore> <attribute> <nsName ns="http://www.garden.co.jp/"/> <nsName ns="http://www.address.co.jp/"/> <text/> </attribute> </zeroOrMore> … </element>
例 2: 名前に制限を設ける
except要素 を子要素に置いて、特定の名前を排除することを考えてみます。例1 のスキーマを、以下のように変えてみたとします。
<element name="喫茶店">
<zeroOrMore>
<attribute>
<nsName ns="http://www.garden.co.jp/">
<except>
<name>広さ</name>
</except>
</nsName>
<text/>
</attribute>
</zeroOrMore>
…
</element>
このようにした場合、以下の記述は妥当でなくなります。 庭:広さ 属性の記述が許されなくなっているためです。
<喫茶店 庭:種類="ローズガーデン" 庭:広さ="10m^2"
xmlns:庭="http://www.garden.co.jp/">
…
例 3: 特定の名前空間のみを排除する
except要素 の中に nsName要素 を入れることで、特定の名前空間に属する名前を排除出来ます。例えば、名前空間 http://bad.com/ に属する要素のみを弾き、それ以外は全て許可したい場合は、以下のような記述が出来るでしょう。
<element name="例">
<zeroOrMore>
<element>
<anyName>
<except><nsName ns="http://bad.com/"/></except>
</anyName>
</element>
</zeroOrMore>
</element>
参考文献
- James Clark and Makoto Murata, ISO/IEC FDIS 19757-2 Document Schema Definition Language (DSDL) -- Part 2: Regular-grammar-based validation -- RELAX NG
- 古林 寛, 「nsName要素 @ ぽかぽか RELAX NG 工房」
LANG
function 要素
関数を定義する要素
- 関数を定義する際に用います。
- マッピング処理を行う関数の場合には、defineMapping 要素を子に指定します。
- 関数宣言のみにも利用することができます。その際は、defineMapping 要素を子に持ちません。
属性
name 属性
関数名を指定します。
制約
- defineFunctions 要素の子としてのみ現れることができます。
子ノード
- arg 要素、return 要素、exception 要素(java 名前空間のみ)defineMapping 要素、defineVariables 要素を子に持ちます。
使用例
例 1: マッピング処理を行う場合
<lang:function name="decodeData">
<lang:arg type="char*" name="ums__buffer" direction="in"/>
<lang:arg type="int" name="ums__bitlen" direction="in"/>
<lang:return type="void"/>
<defineVariables>
<lang:var type="int" name="iData"/>
</defineVariables>
<defineMapping direction="decode" xmlns:txt="http://ums.isas.jaxa.jp/0.4/dat">
<txt:list encode="txt">
<txt:data type="token"/>
<lang:value-of select="iData">
<data type="int"/>
</lang:value-of>
<lang:callFunction expr="setIntValue( iData );"/>
</txt:list>
</defineMapping>
</java:function>
例 1: 関数宣言のみの場合
<lang:function name="setIntValue">
<lang:arg type="int" name="iData" direction="in"/>
<lang:return type="void"/>
<lang:function>
arg 要素
関数の引数を指定する要素
- 関数の引数を定義する際に用います。
- 引数が複数ある場合は、複数定義してください。
属性
type 属性
引数の型(プリミティブ型)を指定します。
class 属性
引数の型(クラス型)を指定します。現在、class 属性を指定可能なのは、java の名前空間のみです。
name 属性
引数名を指定します。
direction 属性
引数の方向を指定します。in、out、inout 以外の値が指定された場合、エラーとなります。
- in : 入力引数です。引数の値を参照する場合に指定します。
- out : 出力引数です。引数の値を更新する場合に指定します。
- inout : 入出力引数です。引数の値を参照し、値を更新する場合に指定します。
制約
- function 要素の子としてのみ現れることができます。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<lang:function name="setValue">
<lang:arg type="int" name="iData" direction="in"/>
<lang:arg type="unsigned int" name="uiData" direction="in"/>
<lang:return type="void"/>
</lang:function>
return 要素
関数の戻り値を指定する要素
- 関数の戻り値を指定する際に用います。
属性
type 属性
関数の戻り値の型を指定します。
制約
- function 要素の子としてのみ現れることができます。
- function 要素内に、複数定義することはできません。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<java:function scope="abstract" name="setIntValue">
<java:arg class="int" name="iData" direction="in"/>
<ava:return type="void"/>
</java:function>
var 要素
変数を定義する要素
- 変数を宣言する際に用います。
属性
type 属性
変数の型(プリミティブ型)を指定します。
class 属性
変数の型(クラス型)を指定します。現在、class 属性を指定可能なのは、java の名前空間のみです。
name 属性
変数名を指定します。
制約
- defineVariables 要素、struct 要素(名前空間が clng の場合のみ)の子としてのみ現れることができます。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<defineVariables>
<lang:var type="int" name="iData"/>
</defineVariables>
array 要素
配列を定義する要素
- 配列を定義する際に用います。
属性
size 属性
配列サイズを指定します。
制約
- defineVariables 要素、struct 要素(名前空間が clng の場合のみ)の子としてのみ現れることができます。
子ノード
- var 要素を子に持ちます。
使用例
例 1:
<defineVariables>
<lang:array size="4096">
<lang:var type="int" name="iData"/>
</lang:array>
</defineVariables>
value-of 要素
変数を表すコンテナ
属性
select 属性
変数アクセスの方法 (C 言語で言うところの左辺値) を指定します。必須です。
制約
Mapping definition の以下の位置のみに現れることができます。
- - lang:value-of - lang:data -
- - lang:value-of - lang:value -
- - dat:container - lang:value-of - ums:data -
- - dat:container - lang:value-of - ums:value -
ただし、ここで dat:container は dat:byte, dat:bit, rng:element, rng:attribute などを示しています。以下は obsolete です。
- - lang:value-of - dat:container - ums:data -
- - lang:value-of - dat:container - ums:value -
子ノード
子にサブコンテナが一つだけ必要です(上記の制約を参照)。
使用例
例 1: mapping の例 (proposal for v0.4)
以下は XML-XML syntax での mapping defition 中のパターンの例です。
<bin:byte length="1">
<lang:value-of select="var">
<data type="int"/>
</lang:value-of>
</bin:byte>
このパターンは双方向 - つまり encode と decode の 両方に使うことができます。 decode では、変数 var に値が読み込まれ encode では、変数 var に値が書き出されます。
これを XML-language syntax に書き直すと以下のようになります。 まず、decode の例。
<bin:byte length="1">
var = <data type="int"/>;
</bin:byte>
また、対応する encode のパターンは以下になります。
<bin:byte length="1">
<data type="int"/> = var;
</bin:byte>
XML-language syntax の方が若干コンパクトです。 また、プログラマには馴染みやすいかもしれません。 一方、mapping definition を XSL の処理する場合、 XML-XML syntax の方が取り扱いやすいです。
謝罪
整備状況が悪くすいません(-KM-)。
callFunction 要素
関数呼び出しを指定する要素
- 関数を呼び出す際に用います。
属性
expr 属性
関数呼び出しを指定します。属性に指定されたそのままの形で、生成ソースコードに出力されます。
制約
- defineMapping 要素の子孫としてのみ現れることができます。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<lang:callFunction expr="setValue( iData );"/>
synchronized 要素
同期を取る処理を指定する要素
- 処理の同期をとりたい場合に用います。
- 制御構造の処理において、"状態"を分岐させた際、関数呼び出しやデータの入出力の同期をとりたい場合に使用する要素です。 すなわち、synchronized 要素を用いた際は、"状態"が1つである必要があります。
属性
- この要素に固有な属性はありません。
制約
- defineMapping 要素の子孫としてのみ現れることができます。
子ノード
- callFunction 要素、value-of 要素を子に持つコンテナ要素を子に持ちます。
使用例
例 1: 関数呼び出しの同期をとる例
以下の例では、nextData() を実行する前に、他に分岐している"状態"がないことを確認します。
<lang:synchronized>
<lang:callFunction expr="nextData();"/>
</lang:synchronized>
C
struct 要素
C言語の構造体を定義する要素
- 構造体を定義する際に用います。
属性
name 属性
構造体名を指定します。
制約
- start 要素の子としてのみ現れることができます。
子ノード
- 複数の array 要素、var 要素を持つことができます。
使用例
例 1:
<clng:struct name="Record">
<clng:array size="4096">
<clng:var type="char" name="strData"/>
</clng:array>
<clng:var type="int32_t" name="iData"/>
<clng:var type="uint32_t" name="uiData"/>
</clng:struct>
Java
class 要素
Java のクラスを定義する要素
- クラスを定義する際に用います。
- class 要素の子孫に定義し、inner class とすることもできます。
- grammar 要素の直下には置いてはなりません。
属性
abstract 属性
抽象クラスであることを指定します。
name 属性
クラス名を指定します。
extends 属性
継承するクラス名を指定します。
制約
- 特にありません。
子ノード
- implements 要素、defineFunctions 要素、defineVariables 要素を子に持ちます。
使用例
例 1:
<ava:class scope="abstract" name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<defineFunctions>
<java:function scope="abstract" name="setStringValue">
...
</java:function>
<java:function scope="abstract" name="setIntValue">
...
</java:function>
</defineFunctions>
<defineFunctions>
<java:function name="decodeData">
...
<defineVariables>
...
</defineVariables>
<defineMapping direction="decode" xmlns:txt="http://ums.isas.jaxa.jp/0.4/dat">
...
</defineMapping>
</java:function>
<java:function name="encodeData">
...
<defineVariables>
...
</defineVariables>
<defineMapping direction="encode" xmlns:txt="http://ums.isas.jaxa.jp/0.4/dat">
...
</defineMapping>
</java:function>
</defineFunctions>
</java:class>
implements 要素
interface の実装を指定する要素
- 実装する interface を指定する際に用います。
- intervace を複数実装する場合は、この要素を複数指定してください。
属性
name 属性
interface 名を設定してください。
制約
- class 要素の子としてのみ現れることができます。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<java:class name="Sample" extends="Data" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<java:implements name="DataInterface"/>
<java:implements name="DataInterface2"/>
...
</java:class>
exception 要素
例外情報を定義する要素
- 例外情報を定義する際に用います。
属性
type 属性
例外クラスを指定します。
制約
- function 要素の子としてのみ現れることができます。
- function 要素内で、複数指定することはできません。
子ノード
- 常に空要素です。子ノードを持ちません。
使用例
例 1:
<java:function scope="abstract" name="setIntValue">
<java:arg class="int" name="iData" direction="in"/>
<ava:return type="void"/>
<ava:exception type="UMSException"/>
</java:function>
umsCodeGenerator
umsCodeGenerator
umsCodeGenerator とは?
umsCodeGenerator は、mappingSchema の処理系です。 mapping definition を入力として、 UMS の定義に従って書かれたデータとプログラミング言語とのマッピングを行い、 データをencode/decodeするためのソースコードを生成します。
このツールは、 mappingSchema の文法体系を曖昧さなく 策定する補助として UMS group 自身が開発を行っています。 mappingSchema の文法は、このツールの進化とともに、より汎用でシンプルなものに成長してきました。
umsCodeGenerator の処理系の全体像

対象とするデータ構造
tableToolsは、その名のとおり「テーブル構造のデータ」を扱うことを対象としています。 具体的には、テキストでテーブル構造を表す形式として、次のような","(カンマ)を区切り文字とした CSV構造が広く利用されています。
csvdata1,11,1.2345
また、XMLでテーブル構造を表すと、例えば次のようになるでしょう。
<Record>
<strData>xmldata1</strData>
<intData>11</intData>
<doubleData>1.2345</doubleData>
</Record>
以上のように、非常にシンプルな構造ですが、データ保存/交換など、多くの場面で利用されています。 tableToolsは、こうしたテーブル構造のデータと、各種プログラミング言語とのマッピング (将来的には、データ構造同士のマッピング)を行うことで、システム開発者が新たにプログラムを 実装する際の負荷を軽減し、システム全体で開発効率の向上をはかることを目標としています。
データ−プログラミング言語間のマッピング
現在サポートされているマッピングは以下のとおりです。
| Java | C | C++ | Perl | |
|---|---|---|---|---|
| Text | ○ | ○ | -- | -- |
| Binary | ○ | ○ | -- | -- |
| XML | -- | -- | -- | -- |
上のマトリックスにおいて、「○」になっているものが、マッピングがサポートされている 組み合わせであることを示します。 また、「○」とある組み合わせは、双方向(decode:データ→プログラミング言語、 encode:プログラミング言語→データ)の変換を行うことが可能です。
利用可能なコンテナ−シーケンシャルデータ
Mapping definition で、 利用可能な要素のうちデータの空間に含まれるもの (コンテナ) は次のとおりです。
利用可能なコンテナ−プログラミング言語
プロトタイプ宣言では以下が利用可能です。
- Java
- class / function / arg / return / exception / array / var
- C
- package / function / arg / return / struct / array / var
- C++
- −
- Perl
- −
また、マッピングでは以下の利用可能なコンテナが言語によらず利用可能です。 今のところ言語固有なコンテナは実装されていません。
- 共通
-
- value-of
- callFunction
利用可能なコンテナ−共通部分
データ及び言語側から、共通に利用可能なコンテナは次のとおりです。
- data
- value (現バージョンでは、シーケンシャルデータ側のみ利用可能)
encodingLibrary
umsCodeGenerator では、以下の encode および W3C datatype の サブセットをサポートするライブラリ (encodingLibrary) がバンドルされています。
| encode | W3C datatype |
Language | |||
|---|---|---|---|---|---|
| Java | C | C++ | Perl | ||
| txt | string | String | char * | -- | -- |
| token | String | char * | -- | -- | |
| byte | byte | int8_t | -- | -- | |
| short | short | int16_t | -- | -- | |
| int | int | int32_t | -- | -- | |
| long | long | int64_t | -- | -- | |
| unsignedByte | short | uint32_t | -- | -- | |
| unsignedShort | int | uint32_t | -- | -- | |
| unsignedInt | long | uint32_t | -- | -- | |
| unsignedLong | BigInteger | uint32_t | -- | -- | |
| double | double | double | -- | -- | |
| signed | byte | byte | int8_t | -- | -- |
| short | short | int16_t | -- | -- | |
| int | int | int32_t | -- | -- | |
| long | long | int64_t | -- | -- | |
| unsigned | unsignedByte | short | uint32_t | -- | -- |
| unsignedShort | int | uint32_t | -- | -- | |
| unsignedInt | long | uint32_t | -- | -- | |
| unsignedLong | BigInteger | uint32_t | -- | -- | |
| ieee754double | float | float | float | -- | -- |
| double | double | double | -- | -- | |
サンプルプログラム
サンプルプログラムやツールのソースコードは以下の標準に従うよう配慮しています。
- JAVA: JAVA2 1.4
- C言語: ISO9899 (C99)
umsCodeGenerator のインストール
必要なソフトウェア
umsCodeGenerator を使うためには、以下のソフトウェアが必要です。
-
Java 2 Platform, Standard Edition (J2SE)バージョン 1.4 以降
Java 実行環境。 環境変数 JAVA_HOME を設定し、環境変数 PATH に $JAVA_HOME/bin を追加して下さい。
また、umsCodeGenerator には以下のソフトウェアが含まれています。 これらについては、環境変数の設定は必要ありません。
-
Apache Antバージョン 1.6.5
Java ベースのソフトウェア build ツール。 -
msv
RELAX NG、RELAX Namespace、RELAX Core、TREX、XML DTDs、XML Schema Part 1のサブセット に対応したスキーマ検証ツール。 -
jing
RELAX NG に対応したスキーマ検証用ツール。 -
trang
スキーマコンバータ。 - Xalan-Java Apache XML Project で開発されている XSLT プロセッサ。
最新版のダウンロード
umsCodeGenerator の最新版は version 0.4(2009032501) です。 以下をダウンロードしてください。
インストール
以下のコマンドで、ダウンロードしたファイルを任意の場所(インストール先のディレクトリになります) に展開して下さい。 umsCodeGenerator/yyyymmddvv というディレクトリが作成されます。
$ tar zxvf umsCodeGenerator-yyyymmddvv.tar.gz
umsCodeGenerator/yyyymmddvv 配下に 環境変数設定用シェルスクリプト(setup.sh と setup_cygwin.sh) を同梱しています。ご利用の環境に応じて、環境変数設定用シェルスクリプトを編集してください。 以下のコマンドで、編集されました環境変数設定用シェルスクリプトを使用して、環境変数を設定すること ができます。
$ source setup.sh
以下のコマンドで、C Compiler を指定してください。
$ export CC="gcc -std=c99 -g"
以下のコマンドを実行すると、umsCodeGenerator が build されます。
$ cd $TABLETOOLS_HOME
$ ant
以下のコマンドで、サンプルが正常に動作するかチェックできます。
途中、実行ログ中にエラーメッセージが出力されますが、異常ケースの試験のためです。
サンプルが全て正常に動作すると、実行ログの最後に "BUILD SUCCESSFUL" と表示されます。
$ ant test
ライセンス
Copyright 2005 Universal Mapping Schema group and ISAS/JAXA
Apache License Version 2.0(「本ライセンス」)に基づいてライセンスされます。
あなたがこのファイルを使用するためには、本ライセンスに従わなければなりません。
本ライセンスのコピーは下記の場所から入手できます。
http://www.apache.org/licenses/LICENSE-2.0
適用される法律または書面での同意によって命じられない限り、本ライセンスに基づいて頒布されるソフトウェアは、
明示黙示を問わず、いかなる保証も条件もなしに「現状のまま」頒布されます。
本ライセンスでの権利と制限を規定した文言については、本ライセンスを参照してください。
umsCodeGenerator の使い方
umsCodeGenerator の使い方
- umsCodeGenerator のインストールを完了してください。
-
環境変数 UMS_THREAD に、"true" または "false" を設定します。
制御構造を含むデータを処理する場合は "true" を設定してください。 制御構造を含まないデータを処理する場合は "true" でも "false" でもかまいません。$ export UMS_THREAD="true"
または$ export UMS_THREAD="false"
-
C 言語版は、以下のコマンドを実行します。
$ txt2clng ums_file -x|-l [output_directory] [-d]
Java 言語版は、以下のコマンドを実行します。$ txt2java ums_file -x|-l [output_directory] [-d]
実行オプション
| オプション | 説明 |
|---|---|
| ums_file | 入力 UMS ファイルを指定します。 |
| -x | XML syntax の UMS ファイルを元にソースコードを生成します。 |
| -l | Language syntax の UMS ファイルを元にソースコードを生成します。 |
| output_directory | 生成ソースコードの出力ディレクトリを指定します。 このオプションを省略した場合は、カレントディレクトリに生成ソースが出力されます。 |
| -d | デバッグ情報を出力するソースコードを生成します。 |
チュートリアル
はじめに
umsCodeGenerator を用いたプログラム作成の流れを説明するために、ここでは簡単なサンプルを示します。 このサンプルでは、 CSV データについて以下のステップで処理を行います。
- 読み込み: 外部からデータを読み込み、umsCodeGenerator で生成されたデコード関数へデータを渡します。
- デコード: デコード関数が mapping definition に従い、データをプログラム変数へ格納します。
- エンコード: エンコード関数が mapping definition に従い、プログラム変数をデータへ格納します。
- 書き込み: umsCodeGenerator で生成されたエンコード関数からデータを受け取り、外部へデータを書き出します。
2番目と3番目のステップが umsCodeGenerator によって生成されたソースコードが処理する部分です。 その他の部分は普通にプログラムを作成します。
チュートリアルを開始するまでに、umsCodeGenerator のインストールを完了しておいてください。
なお、以降で作成するサンプルは umsCodeGenerator/yyyymmddvv/sample/tutorial に含まれています。 このディレクトリには、Java 版の XML syntax、Language syntax、C 版の XML syntax、Language syntax のサンプルが含まれています。
1. 入力データの作成
入力データと出力データの書式はどちらも同じで、"," を区切り文字とした CSV 形式とします。 以下のデータを "sample.csv" という名前でファイルに保存してください。
A,100,1.1
B,200,2.2
C,300,3.3
今回、 mappingSchema で 定義するデータの単位は、各行単位にします(ファイル全体を定義することもできます)。 行の切り出しは外付けで処理し(ステップ 1、4)、 各行の処理を mappingSchema で定義する(ステップ 2、3)ことにします。
2. mapping definition の作成
任意のエディタで mapping definition を作成します。 mapping definition は、XML syntax、Language syntax、C 版、Java 版ともに以下の記述が必要になります。 2.1 以降では、この記述に追記していく形で、Java 版の XML syntax の mapping definition を作成していきます。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4/dat" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
:
</start>
</grammar>
2.1 クラス名を決める
デコード・エンコード関数を持つクラス名を決めます。今回は、"Sample" というクラス名を用います。 (この定義は、C 言語版では不要です。) ソースコードでは以下のように表せます。
class Sample {
:
}
これを、 mapping definition の XML 形式に書き直すと以下になります。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4/dat" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<java:class name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
:
</java:class>
</start>
</grammar>
2.2 エンコード関数、デコード関数の名前を決める
デコード処理、エンコード処理を行う関数の名前を決めます。 今回は、デコード処理を行う関数を"decode"、エンコード処理を行う関数を"encode"という名前にします。
次に、エンコード関数、デコード関数のインターフェースを決めます。 これらの関数のインターフェース(引数の型、引数の名前)は、umsCodeGenerator で以下のように固定です ( mappingSchema の決まりではありません)。
| 言語 | 関数種別 | インターフェース |
|---|---|---|
| C言語 | デコード関数 |
/** * デコード処理を行う。 * * @param ums__buffer 入力データ格納バッファ * @param ums__bitlen 入力データ長(bit) * ※入力データそのもののデータであり、入力格納バッファのサイズではない。 * @param ums__ex 例外情報 * @return デコードデータサイズ(bit) */ ums__bitlen_t decode( ums__bitdata_t *ums__buffer, ums__bitlen_t ums__bitlen, ums__exception_t *ums__ex ) |
| エンコード関数 |
/** * エンコード処理を行う。 * * @param ums__buffer 出力データ格納バッファ * @param ums__bitlen 出力データ格納バッファの長さ(bit) * @param ums__ex 例外情報 * @return エンコードデータサイズ(bit) */ ums__bitlen_t encode( ums__bitdata_t *ums__buffer, ums__bitlen_t ums__bitlen, ums__exception_t *ums__ex ) |
|
| Java | デコード関数 |
/** * デコード処理を行う。 * * @param ums__buffer 入力データ格納バッファ * @param ums__bitlen 入力データ長(bit) * ※入力データそのもののデータであり、入力格納バッファのサイズではない。 * @return デコードデータサイズ(bit) * @exception UMSException デコード処理エラー */ int decode( byte[] ums__buffer, int ums__bitlen ) throws UMSException |
| エンコード関数 |
/** * エンコード処理を行う。 * * @param ums__buffer 出力データ格納バッファ * @param ums__bitlen 出力データ格納バッファの長さ(bit) * @return エンコードデータサイズ(bit) * @exception UMSException エンコード処理エラー */ int encode( byte[] ums__buffer, int ums__bitlen ) throws UMSException |
ソースコードでは以下のように表すことができます。
class Sample {
:
int decode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
}
int encode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
}
}
これを、 mapping definition の XML 形式に書き直すと以下になります。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<java:class name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
:
<defineFunctions>
<java:function name="decode">
<java:arg type="byte[]" name="ums__buffer" direction="in"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
:
</java:function>
<java:function name="encode">
<java:arg type="byte[]" name="ums__buffer" direction="out"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
:
</java:function>
</defineFunctions>
</java:class>
</start>
</grammar>
2.3 データ構造の定義
以下のデータについて、データ構造を mappingSchema の文法に沿った XML 形式で定義します。
A,100,1.1
以下の定義は、セパレータ "," で区切られたリスト形式で、 順に"トークン型"、"整数型"、"浮動小数点型"のデータ構造であることを示しています。
<byte>
<list separator=",">
<data type="token"/>
<data type="int"/>
<data type="double"/>
</list>
</byte>
2.4 プログラミング言語の処理の定義
次に、プログラミング言語の処理を決めます。 ここでは、処理対象のデータ全てを変数に保持する処理を採用します。 そこで、これを保持するための変数を用意することにします。 ソースコードでは以下のように表せます。
class Sample {
String sData;
int iData;
double dData;
int decode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
}
int encode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
}
}
これを、 mappingSchema の XML 形式に書き直すと以下になります。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<java:class name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<defineVariables>
<java:var class="String" name="sData"/>
<java:var type="int" name="iData"/>
<java:var type="double" name="dData"/>
</defineVariables>
<defineFunctions>
<java:function name="decode">
<java:arg type="byte[]" name="ums__buffer" direction="in"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
:
</java:function>
<java:function name="encode">
<java:arg type="byte[]" name="ums__buffer" direction="out"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
:
</java:function>
</defineFunctions>
</java:class>
</start>
</grammar>
2.5 データ構造と言語での処理の対応の定義
次に、データ構造と、プログラミング言語の処理の対応を定義します。 ここでは、データを順に変数と対応させます。 ソースコードでは以下のように表せます。
class Sample {
String sData;
int iData;
double dData;
int decode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
sData = ... ; // 1項目目のデコード
:
iData = ... ; // 2項目目のデコード
:
dData = ... ; // 3項目目のデコード
:
}
int encode( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
:
... = sData ; // 1項目目のエンコード
:
... = iData ; // 2項目目のエンコード
:
... = dData ; // 3項目目のエンコード
:
}
}
これを、 mapping definition の XML 形式に書き直すと以下になります。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4" datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<java:class name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<defineVariables>
<java:var class="String" name="sData"/>
<java:var type="int" name="iData"/>
<java:var type="double" name="dData"/>
</defineVariables>
<defineFunctions>
<java:function name="decode">
<java:arg type="byte[]" name="ums__buffer" direction="in"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
<defineMapping direction="decode">
<dat:byte encode="txt" xmlns:dat="http://ums.isas.jaxa.jp/0.4/dat">
<dat:list separator=",">
<java:value-of select="sData">
<data type="token"/>
</java:value-of>
<java:value-of select="iData">
<data type="int"/>
</java:value-of>
<java:value-of select="dData">
<data type="double"/>
</java:value-of>
</dat:list>
</dat:byte>
</defineMapping>
</java:function>
<java:function name="encode">
<java:arg type="byte[]" name="ums__buffer" direction="out"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="int"/>
<java:exception type="UMSException"/>
<defineMapping direction="encode">
<dat:byte encode="txt" xmlns:dat="http://ums.isas.jaxa.jp/0.4/dat">
<dat:list separator=",">
<java:value-of select="sData">
<data type="token"/>
</java:value-of>
<java:value-of select="iData">
<data type="int"/>
</java:value-of>
<java:value-of select="dData">
<data type="double"/>
</java:value-of>
</dat:list>
</dat:byte>
</defineMapping>
</java:function>
</defineFunctions>
</java:class>
</start>
</grammar>
以上で mapping definition の作成は終了です。 この mapping definition を、Sample.ums という名前でファイルに保存してください。
3. その他のソースコードの作成
デコード関数、エンコード関数以外のソースコードを通常の方法で作成します。 ここでは、以下の処理を行う main メソッドを作成します。
- 入力データをファイルから読み込み、バッファに格納する。
- 入力バッファの内容を表示する。
- デコードメソッドを呼び出す。
- エンコードメソッドを呼び出す。
- 出力バッファの内容を表示する。
3.1 デコード関数・エンコード関数使用時に必要な処理
デコード関数、エンコード関数を使用するにあたって、次の処理を行う必要があります。
- ライブラリクラスの include(C 言語) / import(java)
- 初期化関数の呼び出し
- 終了関数の呼び出し
各プログラミング言語において、ライブラリ、初期化関数、終了関数は、それぞれ以下のようになります。
| 言語 | ライブラリ | 初期化関数 | 終了関数 |
|---|---|---|---|
| C言語 | ums.h | tableTools_init() | tableTools_end() |
| Java | jp.jaxa.isas.ums.runtime.* | UMSLibrary.tableTools_init() | UMSLibrary.tableTools_end() |
main 関数は以下のようになります。
import java.io.*;
import jp.jaxa.isas.ums.runtime.*;
class Main {
private static final int BUFFER_SIZE = 4096;
public static void main( String[] args ) {
String inString = null;
byte[] inBuffer = null;
int inBitlen = 0;
int decodeBitlen = 0;
byte[] outBuffer = new byte[BUFFER_SIZE];
int outBitlen = 0;
int encodeBitlen = 0;
BufferedReader br = null;
UMSLibrary.tableTools_init();
try {
Sample sample = new Sample();
br = new BufferedReader( new FileReader( args[0] ) );
while ( ( inString = br.readLine() ) != null ) {
inBitlen = inString.length() * 8;
inBuffer = inString.getBytes( "US-ASCII" );
System.out.println(
"input(" + inBitlen/8 + "*8+" + inBitlen%8 + "):<" + inString + ">" );
/* call decode method */
decodeBitlen = sample.decode( inBuffer, inBitlen );
outBitlen = BUFFER_SIZE * 8;
/* call encode method */
encodeBitlen = sample.encode( outBuffer, outBitlen );
String outString = new String( outBuffer, 0, encodeBitlen/8, "US-ASCII");
System.out.println(
"output(" + encodeBitlen/8 + "*8+" + encodeBitlen%8 + "):<" + outString.trim() + ">" );
}
} catch ( IOException ex ) {
ex.printStackTrace( System.err );
} catch ( Throwable th ) {
th.printStackTrace( System.err );
} finally {
try {
if ( br != null ) {
br.close();
}
} catch ( Exception ex ) {}
}
UMSLibrary.tableTools_end();
}
}
3.2 例外機構の使い方
エンコード関数・デコード関数は、データが定義にマッチしなかった場合などに例外を発生します。 例外機構を使用するにあたって、次の処理を行う必要があります。
- ライブラリクラスの include(C 言語) / import(java)
- 例外情報保持変数の宣言(C言語のみ)
- 例外情報初期化関数の呼び出し(C言語のみ)
- 例外情報の出力
各プログラミング言語において、ライブラリ、初期化関数、終了関数は、それぞれ以下のようになります。
| 言語 | ライブラリ | 例外情報保持変数型 | 例外情報初期化関数 | 例外情報出力関数 |
|---|---|---|---|---|
| C言語 | umsException.h | ums__exception_t | ums__exception_init | ums__exception_print |
| Java | jp.jaxa.isas.ums.runtime.UMSException | 不要 | 不要 |
main 関数は以下のようになります。
import java.io.*;
import jp.jaxa.isas.ums.runtime.*;
class Main {
private static final int BUFFER_SIZE = 4096;
public static void main( String[] args ) {
String inString = null;
byte[] inBuffer = null;
int inBitlen = 0;
int decodeBitlen = 0;
byte[] outBuffer = new byte[BUFFER_SIZE];
int outBitlen = 0;
int encodeBitlen = 0;
BufferedReader br = null;
UMSLibrary.tableTools_init();
try {
Sample sample = new Sample();
br = new BufferedReader( new FileReader( args[0] ) );
while ( ( inString = br.readLine() ) != null ) {
inBitlen = inString.length() * 8;
inBuffer = inString.getBytes( "US-ASCII" );
System.out.println(
"input(" + inBitlen/8 + "*8+" + inBitlen%8 + "):<" + inString + ">" );
/* call decode method */
decodeBitlen = sample.decode( inBuffer, inBitlen );
outBitlen = BUFFER_SIZE * 8;
/* call encode method */
encodeBitlen = sample.encode( outBuffer, outBitlen );
String outString = new String( outBuffer, 0, encodeBitlen/8, "US-ASCII");
System.out.println(
"output(" + encodeBitlen/8 + "*8+" + encodeBitlen%8 + "):<" + outString.trim() + ">" );
}
} catch ( UMSException ex ) {
ex.print( outBuffer, outBitlen );
ex.printStackTrace( System.err );
} catch ( IOException ex ) {
ex.printStackTrace( System.err );
} catch ( Throwable th ) {
th.printStackTrace( System.err );
} finally {
try {
if ( br != null ) {
br.close();
}
} catch ( Exception ex ) {}
}
UMSLibrary.tableTools_end();
}
}
上記の main メソッドを、"Main.java" という名前で保存してください。
4. umsCodeGenerator の実行
mapping definition から ソースコードを生成するため、以下のコマンドで umsCodeGenerator を実行してください。 カレントディレクトリに、"Sample.java" というファイルが生成されます。
$ txt2java -x Sample.ums
5. コンパイル・実行
これ以降は普通のプログラム開発と同じです。 これまで作成、生成したファイル(sample.csv、Main.java、Sample.java)をカレントディレクトリに格納し、 以下のコマンドを実行してください。
-
C言語
$ gcc -std=c99 -ggdb -o main -Wall -I${TABLETOOLS_HOME}/build/include -I. *.c -L${TABLETOOLS_HOME}/build/lib/ -lums -lumstt
$ ./main < sample.csv -
Java
$ javac -classpath .:$TABLETOOLS_HOME/build/classes Main.java Sample.java
$ java -cp .:$TABLETOOLS_HOME/build/classes Main sample.csv
正しく処理ができていれば、以下が表示されます。
input(9*8+0):<A,100,1.1>
output(9*8+0):<A,100,1.1>
input(9*8+0):<B,200,2.2>
output(9*8+0):<B,200,2.2>
input(9*8+0):<C,300,3.3>
output(9*8+0):<C,300,3.3>
Tips
Tips
1. Emacs + nxml-mode
Emacs + nxml-mode で編集すると、 mapping definition の validation をリアルタイムに行ってくれます。 nxml-mode が読み込む rnc ファイルは、以下のコマンドによって $TABLETOOLS_HOME/schema/rnc 配下に生成されます。
$ ant rnc
mapping definition が 正しい文法で書かれているか、msCodeGenerator がサポートしている範囲に収まっているかを チェックすることができます。 datatypeLibrary の URI と type もチェックの対象です。 ただし、両者が正しい組み合わせで使われているかはチェックされません。
2. 改行コードにマッチする value 要素
本当に改行コードを埋め込むしかないのです。
... <txt:value>
</txt:value>
以下ではありません。
<txt:value>\n</txt:value>
3. サンプルで用いるファイルを自動で生成する方法
サンプルで用いるファイルを、以下のコマンドにより、自動で生成することもできます。
$ createsample -lang -type ums_file output_directry
これにより、以下の構造のサンプルディレクトリに、サンプルで用いるファイルが自動で生成されます。
+ Sample
+ clng
- SampleMain.c
- SampleTest.c
- Makefile
- schemas.xml
- Sample.ums
+ java
- SampleMain.java
- SampleTest.java
- build.xml
- schemas.xml
- Sample.ums
+ data
設計メモ:サンプル自動生成ツール
4. validation プログラム
マッピング定義 を用いて 簡単に validation プログラムを書くことができます。 以下は、1行に ':' で区切られた8項目のデータが並ぶファイルを検証する例です。 JAVA では、以下のようになります。
<?xml version="1.0" encoding="utf-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
import jp.jaxa.isas.ums.runtime.*;
import jp.jaxa.isas.ums.m3.*;
class ValidateSample {
static void validate( byte[] ums__buffer, int ums__bitlen ) throws UMSException {
<defineMapping direction="decode">
<dat:byte encode="txt" xmlns:dat="http://ums.isas.jaxa.jp/0.4/dat">
<dat:list separator=":">
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
</dat:list>
</dat:byte>
</defineMapping>
}
/* 行データ用定型プログラム */
public static void main(String[] args) {
UMSLibrary.tableTools_init();
String fileName = args[0];
String inputBuffer;
byte[] buffer = null;
int inBitlen = 0;
try {
java.io.BufferedReader br
= new java.io.BufferedReader( new java.io.FileReader( fileName ) );
while( ( inputBuffer = br.readLine() ) != null ) {
inBitlen = inputBuffer.length() * 8;
try {
buffer = inputBuffer.getBytes( "US-ASCII" );
validate( buffer, inBitlen );
} catch ( UMSException ex ) {
ex.print( buffer, inBitlen );
ex.printStackTrace( System.err );
}
}
br.close();
} catch ( java.io.IOException ex ) {
ex.printStackTrace( System.err );
}
UMSLibrary.tableTools_end();
}
}
</start>
</grammar>
また、C言語では以下のようになります。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
void validate( char *ums__buffer, int ums__bitlen, ums__exception_t *ums__ex ) {
<defineMapping direction="decode">
<dat:byte encode="txt" xmlns:dat="http://ums.isas.jaxa.jp/0.4/dat">
<dat:list separator=":">
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
<dat:data type="string"/>
</dat:list>
</dat:byte>
</defineMapping>
}
/* 行データ用定型プログラム */
int main() {
char in_buffer[BUFFER_SIZE];
int in_bitlen;
ums__exception_t ums__ex;
tableTools_init();
while ( fgets( in_buffer, BUFFER_SIZE, stdin ) != NULL ) {
in_bitlen = strlen( in_buffer ) * 8 - 8;
in_buffer[in_bitlen/8] = 0;
printf( "input(%d*8+%d):<%s>\n", in_bitlen / 8, in_bitlen % 8 , in_buffer );
initException( &ums__ex );
validate(input_buffer, in_bitlen, &ex);
if ( ums__ex.occured != UMS__STATE_OK ) {
ums__exception_print( &ums__ex, in_buffer, in_bitlen );
continue;
}
}
tableTools_end();
return 0;
}
</start>
</grammar>
5. enocde と decode で同じデータ定義を参照する方法
'define'要素 、 及び 'ref'要素 を 用いて、共通部分を定義、参照することができます。 チュートリアルの例は、以下のように書き直すことができます。
<?xml version="1.0" encoding="UTF-8"?>
<grammar xmlns="http://ums.isas.jaxa.jp/0.4"
datatypeLibrary="http://www.w3.org/2001/XMLSchema-datatypes">
<start>
<java:class name="Sample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<defineVariables>
<java:var class="String" name="sData"/>
<java:var type="int" name="iData"/>
<java:var type="double" name="dData"/>
</defineVariables>
<defineFunctions>
<java:function name="decode">
<java:arg type="byte[]" name="ums__buffer" direction="in"/>
<java:arg type="int" name="ums__bitlen" direction="in"/>
<java:return type="void"/>
<java:exception type="UMSException"/>
<defineMapping direction="decode">
<ref name="mapping">
</defineMapping>
</java:function>
<java:function name="encode">
<java:arg type="byte[]" name="ums__buffer" direction="out"/>
<java:arg type="int[]" name="ums__bitlen" direction="inout"/>
<java:return type="void"/>
<java:exception type="UMSException"/>
<defineMapping direction="encode">
<ref name="mapping">
</defineMapping>
</java:function>
</defineFunctions>
</java:class>
</start>
<define name="mapping">
<dat:byte encode="txt" xmlns:dat="http://ums.isas.jaxa.jp/0.4/dat">
<dat:list separator=",">
<java:value-of select="sData">
<data type="token"/>
</java:value-of>
<java:value-of select="iData">
<data type="int"/>
</java:value-of>
<java:value-of select="dData">
<data type="double"/>
</java:value-of>
</dat:list>
</dat:byte>
</define>
</grammar>
6. define/ref の機能のみ使いたい
"resolveRef.xsl" を使用し、 define/ref の展開を行いたい XML ファイルを XSLT プロセッサにかけてください。
[参照ファイル]
src/xslt/raw/resolveRef.xsl
umsCodeGenerator 0.4
Major Versions
- umsCodeGenerator version 0.4
-
Capability of
- choice
- repeat
- optional
- zeroOrMore
- oneOrMore.
- Method 3: - One pass processing which supports XML, interleave (recurse of self is prohibited), recursive ref-define within finite depth. Sample is shown here.
- tableTools version 0.4
-
This version can only handle simple table type structure.
Both decoding and encoding of sequential data are supported.
On the other hand, following capability was tentatively descoped
- choice
- repeat
- optional
- zeroOrMore
- oneOrMore.
-
Supported Data Structure
- Sequential Data in Text and Binary format - http://ums.isas.jaxa.jp/0.4/dat
-
Supported Processing Language
- C - http://ums.isas.jaxa.jp/0.4/clng
- JAVA - http://ums.isas.jaxa.jp/0.4/java
- umsCodeGenerator version 0.3
-
Most of processing in 'umsCompiler' has been moved into
the XSL stylesheet of 'umsCodeGenerator' version 0.3.
Since XSLT has limited capability in handling of strings,
small portion of processing is still written in JAVA.
This version of umsCodeGenerator supports generation of
decoding library of serial data.
C, JAVA and PERL version was available.
Only Method 2 type processing was supported in this version.
-
Supported Data Structure
- Sequential Data in Text and Binary format - http://ums.isas.jaxa.jp/0.3/dat
-
Supported Processing Language
- Perl - http://ums.isas.jaxa.jp/0.3/perl
- C - http://ums.isas.jaxa.jp/0.3/clng
- JAVA - http://ums.isas.jaxa.jp/0.3/java
-
Supported Data Structure
- umsCompiler version < 0.2
-
Oldest version of this program written in JAVA language.
This version supported two decoding algorithms
- Method 1 (only for input of text data): Converts mapping definition into a regular expression and use regular expression library.
- Method 2: Two pass proccessing for both text and binary data.
Minor Releases
- 2006年11月22日:20061122 版 リリースノート
-
- デコード/エンコード関数のインタフェースを変更しました。
- Xalan、MSV、Jing、Trangを同梱しました。
- W3C datatype の hexBinary 型に対応しました。
- 2006年10月20日:20061020 版 リリースノート
-
- value 要素の制約ファセットをスキーマに追加しました。
- 生成ソースコードを最適化しました。
- 2006年10月06日:20061006 版 リリースノート
-
- umsCodeGenerator として未サポートのタグをチェックする機能を追加しました。
- 例外発生時のメッセージを分かりやすくしました。
- 2006年09月13日:20060913 版 リリースノート
-
- 環境変数 UMS_THREAD の設定が必要になりました。
- umsCodeGenerator によって生成されるソースコードの処理に用いるデータ構造を変更しました。
- 2006年08月16日:20060816 版 リリースノート
-
- 入力ファイル (mapping definition file) のチェック機能を充実させました。
- 2006年07月28日:20060728 版 リリースノート
-
- 20060714 版 UMS 仕様に対応するよう、処理の変更、制約の追加を行いました。
- Java 版の package 指定に対応させました。
- 2006年07月14日:20060714 版 リリースノート
-
- 20060419 版 UMS 仕様に対応するよう、処理の変更、制約の追加を行いました。
- group, interleave, choice, optional, zeroOrMore, oneOrMore, empty について、 「dat」名前空間に対応しました。
- 2006年06月23日:20060623 版 リリースノート
-
- pre 処理のステップを無くし、umsCodeGenerator 生成時の build 速度を改善しました。
- :
- 2005年10月25日: umsCodeGenerator-2005102501.tar.gz
- 内部処理を全面的に見直し無駄な処理を省きました。 interleave を組み込みました。 全般的にタグを入れ子にした場合の試験ケースが甘いので包括的な試験を今後実施します。(-KM-)
- 2005年9月19日:
- スキーマの仕様のドラフトを作成しました( see http://ums.isas.jaxa.jp/ )。 umsCodeGenerator の最新版とほとんど一致していますが、 line タグの代わりに lines タグが導入され、 ツール側とは不一致になっています。(-KM-)
- 2005年9月17日: umsCodeGenerator-2005091701.tar.gz
- エラーメッセージを充実させました。 同梱の encodingLibrary がサポートする型を増やしました。(-KM-)
- 2005年8月3日: umsCodeGenerator-2005080301.tar.gz
- tableTools を umsCodeGenerator に統合しました。 file タグを実装し、mapping definition ファイルから 明示的に出力先ソースファイルの名称を規定できるようにしました。(-KM-)
- 2005年8月1日:
- tableTools/umsCodeGenerator 双方に line タグ、param タグが実装されました。 line タグは、「テキストファイルの1行」に対応するものです。 また、umsCodeGenerator に optional, choice, zeroOrMore, oneOrMore の 機能が実装されました。サンプルに残っていたロケールの依存性を 排除し、環境変数 CC を参照し使用するコンパイラを決めるなど 各種プラットホームへの対応への準備を進めています。(-KM-)
- 2005年7月29日: tableTools-2005072953.tar.gz umsCodeGenerator-2005072953.tar.gz
-
- ロケール非依存化
- 環境変数 CC を参照
- line のサポート
- optional のサポート (umsCodeGenerator のみ)
- 2005年7月23日: tableTools-2005072305.tar.gz umsCodeGenerator-2005072305.tar.gz
- 従来の syntax (XML-XML syntax) に加え、 XML-language syntax をサポートしました。 プログラムの中にスキーマを埋め込む形で使えるので便利です。 oneOrMore, zeroOrMore, choice のサポートしました(umsCodeGenerator)。 (-KM-)
- 2005年7月2日: tableTools-2005070253.tar.gz
-
- XSL の記述を整理圧縮。
- pre XSL の処理を追加。 XSL をメタに記述しておき論理関係をすっきりさせる。 コメント出力の取り扱い、コンテナの取り扱いなど
- post xsl の処理を追加。 言語固有性はここで吸収。
- 2005年6月26日: tableTools-2005062653.tar.gz umsCodeGenerator-2005062653.tar.gz
-
- 例のディレクトリ構造を整理。
- list の実装を変更。 separator 属性、delimiter 属性 に対応。ネストへの対応。
- umsCodeGenerator (制御構造あり向け) と tableTools (制御構造なし向け) を分離。 処理ロジックは可能な限り共通化。 ただし、今のところどちらも制御構造 には対応していない。 C 言語版もコンパイル可能に。
- 2005年6月24日: tableTools-2005062451.tar.gz
-
- JAVA 版において <list/> 要素の処理に対応。 CSV 対応のための separator 属性が導入されました。 が、separator 属性、delimiter 属性とし再定義の 予定であり、これを用いる場合 mapping 定義の re-write が必要になります。
- マッピング定義ファイルを検証するための RELAX NG ファイルを作成しました。
- 例外処理の考え方を整理しました。
- 2005年6月21日:
- 本体とは切り離した encodingLibrary の拡張を始めました (ここに書くべきことではないかもしれません)。
- 2005年4月25日: tableTools-2005042504.tar.gz
-
C 版において <list/> 要素の処理に対応しました。
encodingLibrary (RELAX NG の datatypeLibrary の機能を包含) を
tableTools の本体部分と切り分けました。
これにより、tableTools 本体に手を加えずに、新たな
encodingLibrary を追加することが可能になりました。
- これにより発覚した、サンプル中の datatypeLibrary の誤記を訂正。その他、ヘッダファイルの指定誤りを訂正。
- (C 版のみ) W3C_typeConversionLibrary において、int 型の 値域に含まれない場合、txt エンコードの unsignedInt 型を 正しくデコードできないバグを訂正。
- 2005年4月18日:
- tableTools version 0.4 をリリースしました。 mappingSchema の文法 (version 0.4) は、 これをもとにフリーズします。 今後は、曖昧さを解消するための、記述の追加など、 コンパチビリティを保ちつつ進化させていきます。(-KM-)
- 2005年4月16日: tableTools-20050416.tar.gz
-
- (C 版のみ) typeConversionLibrary 全面見直し。 <data/> 要素、<value/> 要素と datatype の組み合わせによって生じる潜在バグを訂正。
- <value/> - string, token 型の encode 処理の リテラル生成で \ 記号が使われた場合の処理誤りを訂正。
- <defineMapping/> - 文法変更。
- 2005年4月15日: tableTools-2005041501.tar.gz
- 2005年4月13日: tableTools-2005041301.tar.gz
- 2005年03月以前の開発の履歴・記録
制約事項
- <value-of>要素の select 属性で使用できる書式に制限があります。 a.b.c などというように、変数名、構造体メンバアクセスを空白を入れず列挙することしかできません。 例えば、<value-of select="(a).a"/>という記述はできません。
- C言語の typedef はサポートされていません。
- 現在は、Java 版のみエラーメッセージの多言語対応(英語メッセージと日本語メッセージ)を行っています。 C版については、英語メッセージしか出力できません。今後対応を行っていく予定です。
- Java 版の typeConversionLibrary 関数において、文字列処理の encode が、現在は "US-ASCII" となっています。
- dataTypeLibrary の URI と type のチェックは、完全ではありません。
既知のバグ
See Bugzilla.
Developer's Inforamtion
umsCodeGenerator
開発規約
ディレクトリ構成
開発時のディレクトリ構成は以下のようにしてください。 archive ディレクトリには、testAndTar.sh を実行時に作成される tar/gz ファイルが格納されます。 ums ディレクトリは、本ページを構成する forrest ドキュメントを格納します。
isas/archive
isas/umsCodeGenerator/yyyymmddvv
isas/ums
開発言語
C 言語
大雑把に言うと、C 言語の方言を使ってはなりませぬ。 ISO C 1999 に従うべきです。 その全ての機能を使ってよいわけではなく、 拡張された機能の使用は極力避けるべきです。 ISO C 1999 の機能のうち明示的に用いていて良いのは以下の機能です。
- 各種ビット長の整数型
- 可変長配列を持つ構造体 (TBD)
より具体的には gcc -fstd=c99 -Wall にて処理できる ソースをコンパイルすることが要求条件です。 また、int_least16_t と int16_t の違いを意識してください。 単発の関数呼び出しのパラメータの場合は前者で、 巨大な配列をメモリに確保する場合は後者を用いるべきです。
Java
以下で動作すること。
- Java2 1.4
- Java5
2005051901:Java、C、XSL についてのコーディング規約
設計メモ:不要な UMS__ ums__ 接尾辞の削除 (例外名称, 制御条件)
設計メモ:C・Java 命名規約
設計メモ:オブジェクト指向
文字コード
ファイルの文字コードは以下に従ってください。
| ファイル | 文字コード | 改行コード | 備考 |
|---|---|---|---|
| .c .h .java .sh | EUC-JP | LF | vi でも emacs でも日本語表示が可能なため。 |
| .xml .xsl | UTF-8 | LF | XMLプロセッサはすべて、UTF-8 と UTF-16 をサポートすることが保障されているため。 |
2次的な関連情報
開発方針
- 改修は一度にまとめて実施せず、可能な限り細かい単位で行ってください。
- ソースコードの改修を行う際は、まず設計メモを作成してください。
- なるべく説明の文書は軽く、ソースコード自身が説明になるようなものを作成してください。
リビジョン管理
変更を行った際は以下の情報を、変更を行ったファイルの先頭と $TABLETOOLS_HOME/changes.xml に記述してください。
- バージョン(yyyymmddvv)
- 変更者
- 変更内容
変更を行った際は、$TABLETOOLS_HOME/tool/testAll.sh を実行し、デグレがないことを確認してください。 なお、試験パターンが全て通ると、isas/archive ディレクトリに umsCodeGenerator-yyyymmddvv.tar.gz が作成されます。
ソースコードの管理は、Subversion で行っています。
設計メモ:変更履歴のつけ方
文書管理
改修を行った時点で、この forrest ドキュメントの関連する部分を改版してください。
forrest ドキュメントの管理もソースコードと同様、Subversion で行っています。
不具合管理
現在、不具合や機能拡張の管理は ToDo と Bugzilla で行っています。 両者は、以下のように使い分けます。
- ToDo:長期の要対応点
- Bugzilla:短期の要対応点
リリースノートの書き方
Releases ページに載せるリリースノートには、 以下の内容を記述してください。
- 仕様・性能・インターフェースなど、ユーザビリティに関わる情報。
- ヘルプ情報など、ユーザにとって必要な情報。
- ユーザに必要な bugfix の情報(Bugzilla 番号、Bug の概要)。
2006年06月23日 以降のリリースノートは、 pod を使用して作成しています。 pod を使用してリリースノートを作成する際は、pod 形式の yyyymmddvv_ums_release.pod ファイルを作成し、 pod2html が使用可能な環境で以下のコマンドを実行してください。
$ pod2html --css=ums.css --title="yyyymmddvv umsCodeGenerator release" < yyyymmddvv_ums_release.pod > yyyymmddvv_ums_release.html
ソースコード生成
ソースコード生成の概要
umsCodeGenerator は、シェル、Java、XSLT で実装されています。 各実装の処理内容は以下の通りです。
| 実装 | 処理内容 | 備考 |
|---|---|---|
| シェル | コード生成処理全体を実行する Java プログラムを呼び出す | Bourne シェルを使用。C シェルは使用しない。 |
| Java |
コード生成処理全体を実行(バリデータの実行、XSLT 変換など) ファイル出力 XSLT を生成 変数定義 XSLT を生成 |
|
| XSLT |
mapping definition のチェック mapping definition の編集 mapping definition からソースコードへ変換 |
XSLT プロセッサは Xalan-Java を使用する。 実装 XSLT 一覧 |
ソースコードの生成は、以下のステップで行います。
- コード生成を行うJava プログラムの呼び出し
- 実行パラメタの解析
- 作業用ディレクトリの作成
- mapping definition の妥当性検証
- mapping definition にファイル名・行番号埋め込み
- UMS の単純化
- define/ref の展開
- UMS の単純化、define/ref 展開後の妥当性検証
- mapping definition に対応した XSLT の生成・マージ
- mapping definition のチェック処理
- mapping definition を Language syntax へ変換
- ソースコード生成
設計メモ:build〜コード生成までの流れ
1. コード生成を行うJava プログラムの呼び出し
コード生成時に使用する各種ライブラリをパスに設定し、コマンドラインオプションを引数にして コード生成を行う Java プログラムを呼び出します。
[参照ファイル]
src/txt2clng.tmpl
src/txt2java.tmpl
2. 実行パラメタの解析
"txt2lang" の実行オプションの解析を行います。 実行オプションの指定が不適切な場合は、USAGE を表示します。
パラメタの解析には、Jakarta-Commons プロジェクトで提供されている、コマンドラインオプション 解析ライブラリである CLI を使用しています。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/GeneratorMain.java
3. 作業用ディレクトリの作成
コード生成時に作成される一時ファイルを格納する一時ディレクトリを作成します。 作成するディレクトリ名は以下になります。
"$TABLETOOLS_TEMP/yyyyMMddHHmmssSSS乱数(0.0 以上 1.0 未満の double 値)"
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/WorkDirectory.java
4. mapping definition の妥当性検証
MSV と Jing を使用して、mapping definition がスキーマ通り記述されているかどうか の妥当性を検証します。 コマンドラインオプションに指定された組み合わせに応じて、妥当性検証を かけるスキーマを選択します。 各 mapping definition に対応するスキーマの組み合わせは以下の通りです。
| mapping definition | スキーマ |
|---|---|
| XML syntax(C 言語) | dat_xml-clng.rng |
| XML syntax(Java) | dat_xml-java.rng |
| Language syntax(C 言語) | dat_lang.rng |
| Language syntax(Java) | dat_lang.rng |
この時、value 要素の type 属性に指定された値に応じた 制約 facet についても妥当性を検証します。 現在サポートしているデータ型については、 encodengLibrary を参照してください。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/XmlValidator.java
設計メモ:value 要素の制約 facet
5. mapping definition にファイル名・行番号埋め込み
mapping definition の記述ミスチェック時や、エラー情報の出力時に mapping definition ファイルの以下の情報を出力します。
- ファイル名
- 行番号
- 列番号
mapping definition の記述ミスのチェックや、エラー情報を出力するコードの 生成は XSLT で行います。 そのため、XSLT でこれらの情報を取得できるよう、要素の属性値として mapping definition に埋め込みます。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/XmlEditor.java
6. UMS の単純化
ここでは、UMS 仕様書の「4.3. datatypeLibrary 属性」と「4.4. value 要素の type 属性」 についての単純化を実施します。 それぞれの項目に対して、以下の処理を行います。
| 項目 | 処理 |
|---|---|
| 4.3. datatypeLibrary 属性 |
datatypeLibrary 属性を持たない data 要素、value 要素に対して、 datatypeLibrary 属性を持つ直近の祖先要素の datatypeLibrary 属性の値を付与する。 data 要素、value 要素以外に付属している datatypeLibrary 属性を取り除く。 |
| 4.4. value 要素の type 属性 |
type 属性を持たない value 要素に対して、値が token である type 属性を付与し、 datatypeLibrary 属性の値を空文字に置き換える。 |
[参照ファイル]
src/xslt/raw/simplify.xsl
7. define/ref の展開
umsCodeGenerator での処理を簡略化するため、mapping definition で定義されている define 要素と ref 要素の展開を行います。
[参照ファイル]
src/xslt/raw/resolveRef.xsl
設計メモ:XML ファイルの再帰的なコピー
8. UMS の単純化、define / ref 展開後の妥当性検証
UMS の単純化、define /ref の展開を行った後も、スキーマに対して妥当性であるかを 検証します。 各 mapping definition に対応するスキーマの組み合わせは以下の通りです。
| mapping definition | スキーマ |
|---|---|
| XML syntax(C 言語) | simple_dat_xml-clng.rng |
| XML syntax(Java) | simple_dat_xml-java.rng |
| Language syntax(C 言語) | simple_dat_lang.rng |
| Language syntax(Java) | simple_dat_lang.rng |
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/XmlValidator.java
9. mapping definition に対応した XSLT の生成・マージ
9.1 ファイル出力テーブル XSLT の生成
生成されるソースコードのファイル名は、*.ums の拡張子を変更したものになります。 しかし、file タグを用い、特定の部分を指定したファイルに出力することも可能です。
ファイル名の定義は mapping definition 内に記述されるため、mapping definition に 応じたファイルの切り分け処理を行う XSLT を生成します。 ファイルの切り分け処理は、Xalan-Java の拡張機能を使用します。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/FileOutputTableCreator.java
設計メモ:出力ファイルの振り分け
9.2 変数変換テーブル XSLT template の生成
マッピングの定義は、mapping definition の defineMapping 要素内に記述されます。 defineMapping 要素内には、変数名のみが記述されますが、変数の型定義は defineMapping 要素の外部で定義されます。 そのため、XSLT 変換を行う際に defineMapping 要素内に現れる変数がどのような型 であるかを、処理系が知っている必要があります。
そこで、defineMapping 内で使用される変数名と型との対応情報を取得可能な XSLT の template を生成します。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/VarTypeTableCreatorForClng.java
src/java/jp/jaxa/isas/ums/codeGenerator/VarTypeTableCreatorForJava.java
設計メモ:変数変換テーブル
9.3 XSLT template のマージ
XSLT 形式に変換した変数変換テーブルを基本のスタイルシートにマージし、 今回処理用のスタイルシートを作成します。 これは、単純に、基本スタイルシート内に、XSLT の template を挿入する処理です。
"pre_txt2lang.xsl" 中の <xsl:template name="varTypeDefinition"/> という部分を、 9.2 で生成した template に置き換えます。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/Generator.java
10. mapping definition のチェック処理
mapping definition の制約と、 UMS 仕様書の制限のチェックを行います。チェックする項目は、以下の通りです。
- define 要素の子孫に、optional 、oneOrMore、zeroOrMore が記述されていないか。
- loop のネストが 32 を超えていないか?
- byte 要素、list 要素の祖先に bit 要素が記述されていないか?
- bit 要素の encode 属性の値に "txt" が指定されていないか?
- method の値として、"2"、"3"、"4" 以外が指定されていないか?
- umsCodeGenerator がサポートしているタグ以外のタグが記述されていないか?
- 環境変数 UMS_THREAD に "true" 以外の値が設定されている際に、制御構造のタグが指定されていないか?
- UMS 仕様書「7.1.5. start 要素」に記述された、禁止されているパスを含んでいないか?
[参照ファイル]
src/xslt/raw/check_mappingdef.xsl
src/xslt/raw/check.xsl
11. mapping definition を Language syntax へ変換
9.3 でマージされた XSLT を使用し、 XML syntax の mapping definition を、Language syntax へ変換します。 入力 mapping definition が Language syntax だった場合は、mapping definition の内容は 変化しません。
[参照ファイル]
src/xslt/raw/pre_txt2clng.xsl
src/xslt/raw/pre_txt2java.xsl
設計メモ:XML-language Syntax の処理の実装方法に関して
12. ソースコード生成
以下のステップでソースコードを生成します。
- <post:* /> と file 要素を含んだソースコードへ変換
- <post:* /> を展開し file 要素を含んだソースコードへ変換
- file 要素に応じて出力ファイルを振り分け
設計メモ:XSLT デザインパターン(preタグの展開)
設計メモ:スタイルシートの整理
設計メモ:ソースコードに mapping definition をコメントとして出力
設計メモ:tableTools と umsCodeGenerator を切り分ける XSLT template
12.1 <post:* /> と file 要素を含んだソースコードへ変換
ソースコードへ変換するスタイルシートは、言語ごとに用意されています。 トップのスタイルシートは言語ごとに別物が用意されており 以下のようになっています。
| ファイル名 | 役割 |
|---|---|
| txt2clng.xsl | テキスト/バイナリデータとC 言語のマッピング用 |
| txt2chdr.xsl | テキスト/バイナリデータとC 言語のマッピング用(ヘッダファイル生成) |
| txt2java.xsl | テキスト/バイナリデータとJAVAのマッピング用 |
"txt2lang.xsl" は処理が多岐にわたります。 そのため、mapping definition に記述する要素ごとに、それぞれの処理を行う XSLT を作成しています(ファイル名の多くは "要素名.xsl")。
これらの XSLT は "txt2clng.xsl"、"txt2java" の両方から呼び出されるため、 C言語とJAVAの共通部分にどちらか固有なコードを記述してはいけません。 言語毎に異なる処理が必要な場合は、それぞれ専用のテンプレートを用意するか、 後述する post 処理で内容を選択するかのいずれかの方法を用います。 "txt2lang.xsl" では、それぞれの XSLT を xsl:include で含めます。
[参照ファイル]
src/xslt/raw/txt2clng.xsl
src/xslt/raw/txt2chdr.xsl
src/xslt/raw/txt2java.xsl
12.2 <post:* /> を展開し file 要素を含んだソースコードへ変換
C 言語と Java の文法の記述を吸収し、XSLT を共通化するために、マクロを使用します。 しかし、XSLT には標準でマクロの機能がないため、"post" 名前空間の要素を定義し、 マクロの機能を実現します。
post マクロで定義するものは、以下になります。
- 例外処理
- 構造体/クラス変数のアクセス
- 関数/メソッドのインターフェース
この他、強力な以下の2つのマクロがあります。 しかし、使用する頻度は必要最低限にしてください。
| マクロ | 役割 |
|---|---|
| <post:clng/> | 子ノードに任意の C言語 のみのソースコードを記述する |
| <post:java/> | 子ノードに任意の JAVA のみのソースコードを記述する |
[参照ファイル]
src/xslt/m2/secondTransform_clng.xsl
src/xslt/m2/secondTransform_java.xsl
src/xslt/m3/secondTransform_java.xsl
src/xslt/m4/secondTransform_clng.xsl
src/xslt/raw/post_clng.xsl
src/xslt/raw/post_java.xsl
設計メモ:post 処理による XSLT 変換
12.3 file 要素に応じて出力ファイルを振り分け
9.1 で生成された XSLT を使用し、最終的に出力ファイルを振り分けます。
以上でソースコードの生成は終了です。
[拡張機能] デバッグ情報の出力
umsCodeGenerator 実行時に "-d" オプションを付与することにより、デコード/エンコード 処理時に以下の情報を出力するコードを生成する。
- mapping definition の処理位置(行番号、要素名)
- 稼動中のスレッド数
- 稼動中のスレッド番号
- タスク制御関数の実行状況
設計メモ:デバッグ情報の出力
[拡張機能] 生成ソースコードの最適化
「最適化しないオプション」を、umsCodeGenerator 実行時に指定できるようにする案が 出たが、オプションを追加するかどうかは 2006/10/27 現在保留中。 2006/10/27 現在の実装としては、最適化しないオプションを "false" の状態で保持 し、コード生成処理を行っている。
[参照ファイル]
src/java/jp/jaxa/isas/ums/codeGenerator/GeneratorMain.java
設計メモ:生成コードの最適化
デコード / エンコード処理
処理ロジック
umsCodeGenerator は、2種類のロジックのソースコードを生成することができます。 「スレッド処理を行うロジック」と、「スレッド処理を行わないロジック」です。 2つのロジックの特徴は、以下の通りです。
| 処理ロジック | 制御構造を持たないデータ | 制御構造を持つデータ |
|---|---|---|
| スレッド処理を行う | 処理可能 | 処理可能 |
| スレッド処理を行わない | 処理可能 | 処理不可能 |
設計メモ:制御構造の取り扱い
設計メモ:制御構造の処理(Java版)
設計メモ:(C言語版)
設計メモ:case ラベルの命名法
設計メモ:例外に関わる辺りの生成コードイメージ
データモデル
umsCodeGenerator が扱うデータは、以下に分類されます。
| データ種別 | 要素 |
|---|---|
| dat | bit、byte、data、value のみで構成 |
| list | list + dat データ |
| loop | oneOrMore、zeroOrMore、optional + dat データ |
| interleave | interleave + dat データ |
umsCodeGenerator が生成するソースコードでは、dat、list、loop、interleave を、 thread クラスの 変数が束ねる形で状態を保持しています。
[参照ファイル]
src/clng/umsDat.h
src/clng/umsDat.c
src/clng/umsList.h
src/clng/umsList.c
src/clng/umsLoop.h
src/clng/umsLoop.c
src/clng/umsInterleave.h
src/clng/umsInterleave.c
src/clng/umsThread.h
src/clng/umsThread.c
src/java/jp/jaxa/isas/ums/runtime/UMSDat.java
src/java/jp/jaxa/isas/ums/runtime/UMSList.java
src/java/jp/jaxa/isas/ums/runtime/UMSLoop.java
src/java/jp/jaxa/isas/ums/runtime/UMSInterleave.java
src/java/jp/jaxa/isas/ums/runtime/UMSThread.java
設計メモ:データモデルの再設計
設計メモ:クラス図
{kind=link}
要素ごとの処理
bit / byte
設計メモ:push, pop の template から呼び出し
設計メモ:長さのチェック及び method 2 における epos の使用法の変更
data / value
設計メモ:data / value 要素の処理
設計メモ:validate -> restrict -> sync -> 代入の方式
param
設計メモ:制約の実装
list
設計メモ:list の処理
設計メモ:親子関係を見る必要があるタグ処理(template と foreach の使い分け)
choice
設計メモ:choice の処理
設計メモ:親子関係を見る必要があるタグ処理(template と foreach の使い分け)
optional
設計メモ:optional の処理
oneOrMore
設計メモ:oneOrMore の処理
zeroOrMore
設計メモ:zeroOrMore の処理
interleave
設計メモ:interleave の意味と処理
設計メモ:interleave の処理
設計メモ(旧版)
- mapping function 2005062651:mapping function の引数名の仕様変更 (固定)
- 2005062451: 例と本体の切り分け
- 2005062452: tableTools と umsCodeGenerator 並存
- 2005080301: umsCodeGenerator, tableTools の統合
- 2005072953: もろもろ作業メモ (txt:line タグ、encodingLibrary の新インターフェース。param タグ の設計メモを含む)
- 2005070251: XSL を XSL で XSL する方法
- 2006062201: pre 処理による XSL 変換
例外処理
例外処理
ここで述べる例外には、以下の2種類があります。
- mapping definition からのソースコード生成時の例外
- デコード/エンコード処理時の例外
1. ソースコード生成時の例外
ソースコード生成時は、 XSLT で例外を検出します。 例外を検出した際は、エラーメッセージを出力すると共に、コード生成を行う Java プログラムへ例外を通知します。
エラーメッセージの出力形式を統一するために、エラーメッセージ出力用の <xsl:template name="error"> を使用します。 この template を使用して出力するエラーメッセージは以下のようになります。
# Error - mapping definition ファイル名 line:行番号 column:列番号 element:<要素名> "エラーメッセージ."
XSLT が検出する 例外は限られたものです。 原理的には XSLT で判定可能な項目でも、実装が複雑になるような項目は ランタイムで検出します。
[参照ファイル]
src/raw/common.xsl
src/raw/check.xsl
設計メモ:XSLT で検出した例外の処理
2. デコード/エンコード処理時の例外
umsCodeGeneratotr が生成するデコード/エンコード処理では、 各種のランタイムエラーを検出します。 デコード/エンコード処理中に例外を検出した際には、次の情報を収集します。
- 例外発生の有無
- エラーコード
- 例外の詳細情報
- 例外検出時の mapping definition ファイル名
- 例外検出時の mapping definition 行番号
- 例外検出時の mapping definition 列番号
- 例外検出時の mapping definition 要素名
- データの処理位置(bit)
- スタックトレース情報
なお、例外情報は、デフォルトでは次のフォーマットで出力します。
エラーメッセージ
-- input data --
at line 行番号, column 列番号
at byte バイト数, bit ビット数
Address| 00 01 02 03 04 05 06 07 08 09 0a 0b 0c 0d 0e 0f
-------+------------------------------------------------
xxxx | 入出力データのバイナリ表示
|
~ エラー発生箇所の指定
-- mapping definition --
mapping definition ファイル名
at line:行番号, column:列番号, element:<要素名>, "エラーメッセージ"
詳細情報
at line:行番号, column:列番号, element:<要素名>, "エラーメッセージ"
詳細情報
:
2.1 言語ごとの例外処理
デコード/エンコード処理時に検出した例外の処理機構は、C 言語と Java で異なります。 Java では、標準の例外処理機構を用いて処理しますが、C 言語は例外処理機構を備えていません。 そこで、Java と同様な処理になるように、例外処理機構を設けています。
設計メモ: ユーザのためのエラーメッセージ・開発者のためのデバッグメッセージ
2.1.1 C 言語での例外処理
C言語では、構造体 "ums__exception_t" を用いて例外情報を保持します。
[参照ファイル]
src/clng/umsException.h
Java の例外処理機構を模擬するために関数形式マクロを定義し、例外処理を行います。 使用する関数形式マクロは以下の通りです。
なお、本マクロを使用する際には、関数名を格納する変数 "FUNCTION" に、 ユーザーがあらかじめ関数名を格納しておく必要があります。
| マクロ | 役割 |
|---|---|
| throw | 例外を検出した際に、例外情報を送出する。 戻り値が void 型の関数で用います。 |
| throwWithValue | 例外を検出した際に、例外情報を送出する。 戻り値がvoid型以外の関数で用い、指定された値で return する。 |
| catchAndThrow | 受け取った例外情報を、そのまま送出する。 戻り値が void 型の関数で用いる。 |
| catchAndThrowWithValue | 受け取った例外情報をそのまま送出する。 戻り値が void 型以外の関数で用い、で指定された値で return する。 |
| catch | 例外を受け取る。 |
[参照ファイル]
src/clng/umsException.h
2.1.2 Java での例外処理
Java では、Exception クラスを継承した UMSException クラスを定義し、 例外情報を保持します。
[参照ファイル]
src/java/jp/jaxa/isas/ums/runtime/UMSException.java
Java では、例外処理機構を用いて例外処理を行います。
2.2 エラーコード体系
例外の種別ごとに、10進6桁のエラーコードを対応させています。 エラーコードの各桁は、次のルールに基づいて数値を割り振ります。
WWXYZZ
WW: 例外種別
X :ツール
Y :検出箇所
ZZ:通番
以下の番号は、umsCodeGenerator で使用しています。
| 桁 | エラーコード | 説明 |
|---|---|---|
| WW | 10 | ソースコード生成エラー |
| 20 | 致命的エラー | |
| 30 | データが定義とマッチしない | |
| X | 1 | umsCodeGenerator |
| Y | 1 | datatypeLibrary関数 |
| 2 | decode・encode関数 | |
| 3 | 生成ソースコード | |
| 4 | ユーザーが作成するソースコード |
umsCodeGeneratorに標準で定義されている、例外検出場所、エラーコード、 エラーメッセージは以下の通りです。
| 例外種別 | 例外検出ファイル | エラーコード | エラー種別 |
|---|---|---|---|
| ソースコード生成エラー | datatypeLibrary関数 | 101101 | データのbit長が定義と一致しない |
| ソースコード生成エラー | datatypeLibrary関数 | 101103 | データのbit長が定義を超える |
| ソースコード生成エラー | decode・encode関数 | 101209 | コンテナのネストが深すぎる |
| ソースコード生成エラー | decode・encode関数 | 101211 | ループのネストが深すぎる |
| 致命的エラー | datatypeLibrary関数 | 201104 | 書き込みバッファを超過する |
| 致命的エラー | decode・encode関数 | 201204 | 書き込みバッファを超過する |
| 致命的エラー | decode・encode関数 | 201205 | 読み込みバッファを超過する |
| 致命的エラー | decode・encode関数 | 201206 | 配列のサイズを超過する |
| 致命的エラー | decode・encode関数 | 201900 | 内部エラー |
| データが定義とマッチしない | datatypeLibrary関数 | 301100 | バイトのアライメントが不適切 |
| データが定義とマッチしない | datatypeLibrary関数 | 301102 | データが定義されたパターンとマッチしない |
| データが定義とマッチしない | datatypeLibrary関数 | 301105 | データの型が定義とマッチしない |
| データが定義とマッチしない | datatypeLibrary関数 | 301172 | バッファの読み込み開始位置が不適切 |
| データが定義とマッチしない | decode・encode関数 | 301200 | バイトのアライメントが不適切 |
| データが定義とマッチしない | 生成ソースコード | 301300 | bit長が不適切 |
2.3 エラーメッセージの多言語対応
多言語対応を実現するため、日本語メッセージと英語メッセージを 各国言語用プロパティファイルに用意します。 ファイルには、次のようにエラーコードとエラーメッセージを記述します。 メッセージの取得は、エラーコードをキーに行います。
エラーコード=エラーメッセージ
各国言語用メッセージファイルは、次のようになります。 これらのファイルは、各プログラミング言語共通で使用します。
| 言語 | ファイル名 | ファイルの記述 |
|---|---|---|
| 日本語 | UMSException_jp.properties |
101101=コンテナのlengthに指定されたビット長(bitlen)がencodeに 指定されたデータ型の固定ビット長(typelen)と等しくありません。 コンテナのlengthに指定した値を修正してください。 101103=コンテナのlengthに指定されたビット長(bitlen)がデータ型の 最大ビット長(maxlen)を超えています。 コンテナのlengthに指定した値を修正するか、データ型を変えてください。 : |
| 英語 | UMSException_en.properties |
101101=It is not equal to fixed bit length (typelen) of the data type from which bit length (bitlen) specified for length of the container is specified for encode. Please correct the value specified for length of the container. 101103=Bit length (bitlen) specified for length of the container exceeds maximum bit length (maxlen)of the data type. Please correct the value specified for length of the container or change the data type. : |
[参照ファイル]
lang/UMSException_en_US.properties
lang/UMSException_ja_JP.properties
Type Conversion Library
1. Type Conversion Library (共通処理)
UMS では、RELAX NG 同様、データ型に関する処理が 言語そのものから切り離されています。つまり、 各プログラミング言語ごとに、
- encodeと、datatype
- datatypeと、プログラミング言語のデータ型
の変換ルール(処理ロジック)を決める必要があり、 各々の組み合わせごとに変換のルールを決めておく必要があります。 これを Type Conversion Library と呼んでいます。 umsCodeGenerator では、これを言語本体とは別の XSLT で定義します。
共通処理は umsCodeGenerator 本体の XSLT から 直接呼び出される Type Conversion Library の入り口です。 umsCodeGenerator 本体の XSL は、datatypeLibrary 属性やその他の値を、 パラメータ 'library' などを用いて、template に引き渡します。 共通処理の template は、'library' の値を用いて、 各 Type Conversion Library 用の XSLT を呼び出します。 未定義の Type Conversion Library が指定された場合、 エラーメッセージを出力します。
新たな Type Conversion Library を、組み込む場合、この XSLT を変更します。
設計メモ: ソースコードのメタな記述 (添付資料)
1.1 typeConversion_lang.xsl
<stylesheet>
<include href="file://localhost/W3C_typeConversion_lang.xsl" />
<template name="initLibrary" />
<template name="encode2valuetypeConversion"
param="library, datatype, encode, cont10, cont20, constant"/>
<template name="encode2datatypeConversion"
param="library, datatype, encode, cont10, cont20"/>
<template name="datatype2langtypeConversion"
param="library, datatype, langtype, varname"/>
<template name="langtype2datatypeConversion"
param="library", datatype, langtype, varname"/>
<template name="datatype2encodeConversion"
param="library, datatype, encode, cont10, cont20"/>
<template name="valuetype2encodeConversion"
param="library, datatype, encode, cont10, cont20, constant"/>
</stylesheet>
1.2 typeConversion_chdr.xsl
<stylesheet> <include href="file://localhost/W3C_typeConversion_chdr.xsl" /> <template name="useLibrary" /> </stylesheet>
2. Type Conversion Library (個別処理)
実際に、どのような処理を行うかは、 各々の Type Conversion Library 毎に個別に指定します。 umsCodeGenerator に同梱のサンプルでは W3C のデータ型の 一部が作りこまれています。
いずれの template も、パラメータ datatype を持っています。 これは、もともとマッピング定義の data 要素や、 value 要素の type 属性の値を umsCodeGenerator 本体の XSL が読み取ったものです。使用可能なデータ型の名前は 各 type conversion library にて定義します。 未定義の datatype が指定された場合、 エラーメッセージが出力されます。
この XSL ファイルに記載される関数呼び出しは 対応するライブラリで定義された関数のみです。
<value /> 要素で指定される固定パターンを プログラミング言語のリテラルに置き換えるのはこの スタイルシートです。と、いうのは、どのような 変換が必要かは type によって決まるからです。 これは、文字列の処理なので XSL のみでは解決できず、 JAVA のソースコードを呼び出しています。
2.1 W3C_typeConversion_lang.xsl
<stylesheet>
<template name="W3C_initLibrary"/>
<template name="W3C_dataTypeDefinition"
param="datatype"/>
<template name="W3C_encode2valuetypeConversion"
param="datatype, encode, cont10, cont20, constant"/>
<template name="W3C_encode2datatypeConversion">
param="datatype, encode, cont10, cont20"/>
<template name="W3C_datatype2langtypeConversion">
param="datatype, langtype, varname"/>
<template name="W3C_langtype2datatypeConversion">
param="datatype, langtype, varname"/>
<template name="W3C_datatype2encodeConversion">
param="datatype, encode, cont10, cont20"/>
<template name="W3C_valuetype2encodeConversion">
param="datatype, encode, cont10, cont20, constant"/>
</stylesheet>
2.2 W3C_typeConversion_chdr.xsl
<stylesheet> <template name="W3C_useLibrary"/> </stylesheet>
3. Type Conversion Library (Library Function)
エンコードされたデータを言語から読み書きする作業は、 直接書き下すことで、最も最適化された処理を行うことができます。 しかし、種々の場合に対応しようとすると、直接ソースコードを 書き出すよりも、ライブラリ関数として切り出しておく方が 検証とソースコードの可読性が向上します。そこで、umsCodeGenerator に同梱のサンプルでは、殆どの処理がプログラミング言語 そのもので記述された typeConversionLibrary を 呼び出す形式を採用しています。
3.1 W3C_typeConversionLibrary.{h,c}
void ums__W3C_typeConversionLibrary_init(void);
void ums__W3C_typeConversionLibrary_end(void);
char *ums__W3C_txtEncode_stringType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
char *ums__W3C_txtEncode_tokenType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
int32_t ums__W3C_txtEncode_intType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
uint32_t ums__W3C_txtEncode_unsignedIntType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
double ums__W3C_txtEncode_doubleType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
int32_t ums__W3C_signedEncode_intType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
uint32_t ums__W3C_unsignedEncode_unsignedIntType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
double ums__W3C_ieee754doubleEncode_doubleType
(ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_stringType_txtEncode
(char * str, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_tokenType_txtEncode
(char * str, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_intType_txtEncode
(int32_t num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_unsignedIntType_txtEncode
(uint32_t num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_doubleType_txtEncode
(double num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_intType_signedEncode
(int32_t num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_unsignedIntType_unsignedEncode
(uint32_t num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_doubleType_ieee754doubleEncode
(double num, ums__dat_t *dat, int epos, ums__exception_t *ex);
void ums__W3C_txtEncode_stringValue
(ums__dat_t *dat, int epos, char *literal, ums__exception_t *ex);
void ums__W3C_txtEncode_tokenValue
(ums__dat_t *dat, int epos, char *literal, ums__exception_t *ex);
void ums__W3C_txtEncode_intValue
(ums__dat_t *dat, int epos, int32_t literal, ums__exception_t *ex);
void ums__W3C_txtEncode_unsignedIntValue
(ums__dat_t *dat, int epos, uint32_t literal, ums__exception_t *ex);
void ums__W3C_txtEncode_doubleValue
(ums__dat_t *dat, int epos, double literal, ums__exception_t *ex);
void ums__W3C_signedEncode_intValue
(ums__dat_t *dat, int epos, int32_t literal, ums__exception_t *ex);
void ums__W3C_unsignedEncode_unsignedIntValue
(ums__dat_t *dat, int epos, uint32_t literal, ums__exception_t *ex);
void ums__W3C_ieee754doubleEncode_doubleValue
(ums__dat_t *dat, int epos, double literal, ums__exception_t *ex);
3.2 Type Conversion Library (Library Function)
public class W3C_TypeConversionLibrary {
public static String txtRead(UMSDat dat, int epos)
throws UMSException;
public static String txtEncode_stringType(UMSDat dat, int epos)
throws UMSException;
public static String txtEncode_tokenType(UMSDat umsDat, int epos)
throws UMSException;
public static int txtEncode_intType(UMSDat umsDat, int epos)
throws UMSException;
public static double txtEncode_doubleType(UMSDat umsDat, int epos)
throws UMSException;
public static int signedEncode_intType(UMSDat umsDat, int epos)
throws UMSException;
public static double ieee754doubleEncode_doubleType(UMSDat umsDat, int epos)
throws UMSException;
public static void bitWrite(long num, UMSDat umsDat, int epos)
throws UMSException;
public static void stringType_txtEncode(String str, UMSDat umsDat, int epos)
throws UMSException;
public static void tokenType_txtEncode(String str, UMSDat umsDat, int epos)
throws UMSException;
public static void intType_txtEncode(int num, UMSDat umsDat, int epos)
throws UMSException;
public static void doubleType_txtEncode(double num, UMSDat umsDat, int epos)
throws UMSException;
public static void intType_signedEncode(int num, UMSDat umsDat, int epos)
throws UMSException;
public static void doubleType_ieee754doubleEncode(double num, UMSDat umsDat, int epos)
throws UMSException;
public static void txtEncode_stringValue(UMSDat dat, int epos, String literal)
throws UMSException;
public static void txtEncode_intValue(UMSDat dat, int epos, int literal)
throws UMSException;
public static void txtEncode_doubleValue(UMSDat dat, int epos, double literal)
throws UMSException;
public static void signedEncode_intValue(UMSDat dat, int epos, int literal)
throws UMSException;
public static void ieee754doubleEncode_doubleValue(UMSDat dat, int epos, double literal)
throws UMSException;
}
開発の流れ
開発の流れの概要
(-- 現在の開発体制の陣容では --)
umsCodeGeneratorの実装は、ボトムアップで進める方が効果的です。 すなわち、最初からスタイルシートを作成し始めるのではなく、 まずは、mapping definition に従った入力データを処理するソースプログラム (umsCodeGeneratorのアウトプットのイメージ)を作成し、 両者を結び付けるためのスタイルシートを完成させていく、 というアプローチを取っています。 実装の流れを整理すると、次のようになります。
- 入力データの作成
- mapping definition の作成
- ソースプログラムの作成
- スタイルシートの作成
- 動作確認
この作業を、徐々に mapping definition の記述を(UMS文法仕様に従って)リッチにしながら、 イテレーティブに実施していきます。 これにより、仕様の漏れがないこと、かつ、正常に動作することを確認しながら作業を進めていくことができます。 また、この作業で作成した mapping definition と入力データとは、そのままテストデータとして利用します。
1. 入力データの作成
入力データの作成は、mapping definition の作成と同時並行的に行います。 下の例では、入力データを持たないUMSを定義しているため、入力データは不要になります。
2. mapping definition の作成
次に、mapping definition を作成します。 簡単のため、入力データを持たない次のような mapping definition を考えます。
<grammar xmlns="http://ums.isas.jaxa.jp/0.4">
<start>
<java:class scope="abstract" name="XmlSample" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<defineVariables>
<java:var name="rec" class="Record"/>
</defineVariables>
</java:class>
</start>
</grammar>
3. ソースプログラムの作成
上で作成した入力データを decode/encode するためのソースプログラムを作成します。 このとき、mapping definition との関係を意識するため、mapping definition 上の要素名、属性名を コメントとして残しながら実装します。 これにより、XSLT 変換を意識しながら実装することができます。 データ変換に関するところは、datatypeLibraryの関数を呼び出すように記述します。
同時に、これを呼び出すための main 関数と、この中から呼び出されるユーザ関数を作成します。
スタイルシートの作成前に、実際にソースプログラムをコンパイル、実行し、 入力データを正しく処理できることを確認しておきます。 本章では、ソースプログラムの添付は省略します。
4. スタイルシートの作成
スタイルシートの作成の前に、上で作成した mapping definition のスキーマを考えます。 一般的な mapping definition の文法ではなく、今回作成するプロセッサが処理できる範囲に 限った文法とします。 これは、XSLT の作成をスムーズに行うためだけでなく、mapping definition を XSL 変換にかける前に、 処理系がこれを正しく処理できるかどうか、文法チェックを行うためのものとしても利用できます。
このようにして作成した RELAX NG の構造を保ったまま、以下のような置き換えを行い、 XSLT を完成させていきます。
<element name="a"/>
→ <xsl:foreach select="a"/>
※スキーマ上、a要素は複数出現することはできないが、XSLT はa要素を複数許容してしまうので注意。
事前にvaridationではじく方が良い。
<zeroOrMore>
<element name="a"/>
</zeroOrMore>
→ <xsl:foreach select="a"/>
<optional>
<attribute name="@a"/>
</optional>
→ <xsl:if test="@a">出力する文</xsl:if>
<choice/>
→ <xsl:choose/>
<define name="xxx"/> と <ref name="xxx"/> の組
→ <template name="xxx"/> と <call-template name="xxx"/> の組
<element name="a">
<element name="b"/>
<element name="c"/>
</element>
→ <xsl:for-each select="a"><xsl:for-each select="b"/></xsl:for-each>
→ <xsl:for-each select="a"><xsl:for-each select="c"/></xsl:for-each>
これにより、以下のような XSLT を作成します。
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform" xmlns:fo="http://www.w3.org/1999/XSL/Format" xmlns:ums="http://ums.isas.jaxa.jp/0.4" xmlns:java="http://ums.isas.jaxa.jp/0.4/java">
<xsl:output method="text"/>
<xsl:template match="/">
<xsl:for-each select="ums:grammar">
<xsl:for-each select="ums:start">
<xsl:for-each select="java:class"><xsl:text></xsl:text>
<xsl:if test="@scope">
<xsl:value-of select="@scope"/>
<xsl:text> </xsl:text>
</xsl:if>class <xsl:value-of select="@name"/> {
<xsl:for-each select="ums:defineVariables">
<xsl:for-each select="java:var">
<xsl:choose>
<xsl:when test="@type">
<xsl:value-of select="@type"/>
</xsl:when>
<xsl:when test="@class">
<xsl:value-of select="@class"/>
</xsl:when>
</xsl:choose>
<xsl:text> </xsl:text>
<xsl:value-of select="@name"/>;
</xsl:for-each>
</xsl:for-each>
}
</xsl:for-each>
</xsl:for-each>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
5. 動作確認
作成した XSLT を使用して XSLT 変換を行い、mapping definition からソースコードを作成します。 生成されたソースプログラムをコンパイル、実行し、入力データを正しく処理できることを確認します。
Todo List
To do
See http://eda.plain.isas.jaxa.jp/bugzilla for bug tracking.
Following tasks are listed in lower priority.
medium
- [code] チェックをしていない、固定長バッファによる処理
- [code] List 処理のライブラリをスッキリさせる(epos を Thread に持たせる、pushContainer 等の機能分割)
- [code] Interleave 処理のライブラリをスッキリさせる
low
- [code] XML version
- [code] Support C++
- [code] Support Perl
- [code] Recursive version
- [docs] Support of restriction of output only element
- [docs] howto のサンプル作り、第2節書き換え、その他チェック
- [code] バイトオーダ、ビットオーダって何?
- [code] バイトアラインされていない場合の取り扱い
- [code] 配列はあれでよかったのか?
- [code] Relax NG文法の継承の記述方法(なんだっけ、これ?)
保留事項
- ツールの分際で ums__ あるいは UMS__ という予約語を使うのは如何なものかと。 あと、umsCodeGenerator, tableTools の双方が tableTools_init() などという関数名を使っている。 命名規約の整理はある段階で必要。
- 異なる開発者が作成したtypeConversionLibraryのエラー番号は、衝突する可能性があります。
- どの例外をユーザ側に戻せば良いか自明でない。
- encodingLibrary の XSL において、template 内で param を直接参照すると 実行環境により、エラーになることがあります。 一度別の変数に代入し、参照すれば大丈夫です。 原因は不明なので、現在はこの処理のままにしています。
- ant から ant が呼べません(cygwin)。現在は、ant から ant を呼ばないようにしています。
Related Information for usage and development of mappingSchema
SSH
Subversion
- Subversion によるバージョン管理(Japanese)
- Subversion によるバージョン管理(Japanese)
XML Editor
nxml mode in Emacs
- Emacs/nXML(Japansese)
- nxml-mode(Japanese)
psgml mode in Emacs
- Usage of PSGML mode(Japansese)
- psgml-mode(Japanese)
XMLspy
- Altova
- Toshiba Solutions(Japansese)
Others
Sibling of mappingSchema under discussion
Timing
Requirement of a data processor
Design Results of this data processor
Example of Parallel Processing (Variable period processing + constant period processing)
Mail Archive
xml2fits
Page for XML2FITS Developers and Users
What is XML2FITS
XML2FITS is a configurable format conversion tool from XML format to FITS format with binary extensions (Figure 1). Structure of input data of this tool is specified by an XML schema language -- RELAX NG –and that of output is also specified by a schema described in XML. This tool is configured by a file named Mapping Schema created from the input schema and the output schema.

Figure 1
ADASS2004
Installation of XML2FITS
Installation
.
Required Softwares
Following software is required for usage of the program.
- J2SE 1.4.2 (J2SE) (Environment Variable: JAVA_HOME; installation memo)
- Apache Ant 1.6 (Environment Variable: ANT_HOME; installation memo)
- CFITSIO 2.5 (installation memo)
- JUnit 3.8 (installation memo)
- Jakarta log4j 1.2 (included in the distribution, no individual install need)
- Jakarta Commons Logging 1.0 (included in the distribution, no individual install need)
- msv
- jing
All of the executable of the software above should be included into the command path (eg. Environment Variable: PATH of shell).
Sample usage of umsCodeGenerator
Sample Files
| Schema of Input | xmlfits-input-20040825.rng | Input Data | xmlfits-input-20040825.xml |
|---|---|---|---|
| mapping definition | xmlfits-input-20040825.ums | ||
| Schema of Output | xmlfits-input-20040825-fits.ums | Output Data | xmlfits-input-20040825.head(only FITS header) |
A mapping definition file can be created from schema of input and schema of output. On the other hand, mapping definition file can be split into schema of input (description of external data) and schema of output (description of interface with program language).
Referrence
FITS
- Tutrial in Japanese http://www.fukuoka-edu.ac.jp/~kanamitu/fits/tebiki2/1-gaiyou.html